
정확도 (Accuracy)
29 Mar 2020 | Machine--Learning Evaluation--Metric성능 평가 지표 (Evaluation Metric)은 모델이 분류인지 회귀인지에 따라 여러 종류로 나뉜다. 회귀의 경우는 대부분 실제값과 예측값의 오차 평균값에 기반한다. 예를 들어 오차의 제곱 값에 루트르 ㄹ씌운뒤 평균오차를 구하는 등의 방법을 사용한다.
분류의 평가는 실제 결과 데이터와 예측 결과 데이터가 얼마나 정확하고 오류가 적게 발생하는가에 기반하지만, 단순히 이러한 정확도만 가지고 판단하기에는 위험할 수 있다. 특히 이진 분류에서는 정확도보다 다른 성능 평가 지표가 더 중요시 되는 경우가 많다. (예시들은 거의 다 이진 분류)
분류의 성능 평가 지표는 다음이 있다.
- 정확도 (Accuracy)
- 오차행렬 or 혼동행렬 (Confusion Matrix)
- 정밀도 (Precision)
- 재현율 (Recall)
- F1 스코어
- ROC AUC
위의 성능 지표들은 이진/멀티 분류 모두에 적용되는 지표이지만 특히 이진 분류에서 더욱 강조되는 지표이다.
정확도 (Accuracy)
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표이다.
\[정확도 (Accuracy) = \frac{예측 결과가 동일한 데이터 수}{전체 예측 데이터 수}\]정확도는 직관적으로 모델 예측 성능을 나타낸다. 하지만 이진 분류의 경우 데이터의 구성에따라 ML 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않도록 해야한다. 특히 레이블이 불균형한 데이터셋에 대해서는 성능수치로 사용돼서는 안된다. 예를 들면, 90개의 데이터 레이블이 0이고 나머지 10개의 데이터 레이블이 1일 때, 학습하지 않고 무조건적으로 0이 답이라고 뱉는 ML 모델은 해당 데이터 셋에 대해서 (학습을 하지 않음에도 불구하고) 90%의 정확도를 보인다. 이러한 정확도의 한계점을 극복하기 위해 여러가지 분류 평가 지표와 함께 적용되어야 한다.
오차 행렬 (Confusion Matrix)
이진 분류에서 성능 지표로 잘 활용되는 오차행렬은 분류 모델이 예측을 수행하면서 얼마나 혼동되고 있는지를 보여주는 지표다. 예측 오류가 얼마인지와 어떠한 유형의 예측 오류가 발생하고 있는지도 알려준다.
정밀도와 재현율
Precision 정밀도 : TP / (FP + TP)
Recall 재현율 : TP / (FN + TP)
정밀도는 positive라고 예측한 데이터 중 실제 positive인 데이터의 비율을 의미한다. Positive 예측 성능을 더욱 정밀하게 측정하기 위한 평가 지표로 양성 예측도 라고도 한다.
재현율은 실제 positive 데이터 중 positive 라고 예측한 데이터의 비율을 의미한다. 민감도(Sensitivity) 또는 TPR(Ture Positive Rate)라고도 한다.
재현율이 중요 지표인 경우는 실제 양성 데이터를 음성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우이다. 예를 들어, 암 판단 모델이 존재한다. 보통은 재현율이 정밀도보다 중요한 경우가 많지만, 정밀도가 더 중요한 지표인 경우는 스팸메일 여부 판단 등이 있다. 스팸메일이 아닌 일반 메일을 스팸메일로 분류하면 업무에 차질이 생길 수 있다.
재현율과 정밀도 모두 TP를 높이는 데 초점을 맞추지만 재현율은 FN을 낮추는데, 정밀도는 FP를 낮추는 데 초점을 맞추고 있다. 즉, 둘은 서로 보완적인 지표로 많이 적요이 된다. (둘 다 높아야 좋음)
precision_recall_curve

사이킷런에서 제공하는 precision_recall_curve() API이다. 입력 파라미터는 실제 클래스값 배열과 positive 칼럼의 예측 확률 배열이고 반환 값은 정밀도와 재현율을 임곗값별로 반환한다.
이 때, positive 칼럼의 예측 확률 배열은 predict_proba(x_test)[:,1]로 구할 수 있다. precision_recall_curve()는 보통 0.11~0.95 정도의 임곗값을 담은 numpy ndarray와 이 임곗값에 해당하는 정밀도 및 재현율 값을 담은 ndarray를 반환한다.
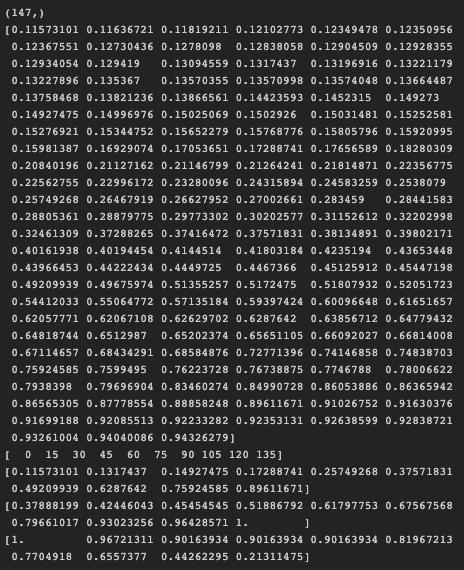
임곗값에 따라 정밀도와 재현율의 수치가 변경되는 것을 볼 수 있다. (trade-off)
F1 스코어
F1 스코어는 정밀도와 재현율을 결합한 지표이다. 둘 중 어느 한 쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가진다.
\[F1 = \frac{2}{\frac{1}{recall} + \frac{1}{precision}} = 2 * \frac{precision*recall}{precision+recall}\]A 모델이 정밀도가 0.9, 재현율이 0.1 이고 B 모델이 정밀도가 0.5, 재현율이 0.5 인 경우. 두 모델의 F1 스코어는 각각 0.18, 0.5로 B 모델이 A에 비해 우수한 스코어를 가진다. 사이킷런에서는 f1_score()라는 API를 제공한다.
ROC 곡선과 AUC
ROC 곡선(Receiver Operation Characteristic Curve)은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지를 나타낸 곡선이다. FPR을 x축, TPR을 y축으로 잡는다.
여기서 TPR은 재현율 또는 민감도라고 불린다. 그리고 이 민감도에 대응하는 지표로 TNR(True Negative Rate)라고 불리는 특이성(Specificity)가 있다.
- 민감도(TPR)은 실제값 양성이 정확히 예측되어야 하는 수준을 나타낸다. (질병이 있는 사람은 질병이 있는 것으로 양성 판정)
- 특이성(TNR)은 실제값 음성이 정확히 예측되어야 하는 수준을 나타낸다. (질병이 없는 사람은 없는 것으로 음성 판정)
TNR = TN / (FP + TN)
FPR = FP / (FP + TN) = 1 - TNR = 1 - 특이성
ROC 곡선의 대각선은 ROC 곡선의 최저값을 의미한다. 이는 동전을 무작위로 던져 앞/뒤를 맞추는 랜덤 수준의 이진 분류의 ROC 직선이다 (AUC는 0.5). ROC 곡선이 이 직선에 가까울수록 성능이 떨어지는 것이며 멀어질수록 성능이 뛰어나다.
ROC 곡선은 분류 결정 임곗값을 변경해가면서 FPR을 0~1 사이로 변경하여 TPR의 변화 값을 구한다. 분류 결정 임곗값은 Positive 예측값을 결정하는 확률의 기준이기 때문에 FPR 값을 0으로 만드려면 이 임곗값을 1로 지정하면 된다. 반대로 FPR 값을 1로 만드려면 TN을 0으로 만들면 되는 데 이는 임곗값을 0으로 지정하면 된다. 그렇게 되면 positive 확률 기준이 너무 낮아서 모두 다 positive로 예측하기 때문에 negative 예측은 없게 되고 결국 TN 값은 0이 된다.
사이킷런에서는 ROC 곡선을 구하기 위해 roc_curve() API를 제공한다.

[ROC curve 그리기]
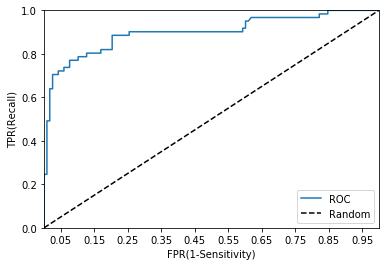
AUC
일반적으로 ROC 곡선은 FPR과 TPR의 변화값 비교에 이용하며 분류의 성능지표로는 곡선 아래 면적인 AUC 값으로 결정한다. AUC (Area Under Curve) 값은 ROC 곡선 밑의 면적을 구한 것으로 일반적으로 1에 가까울수록 좋다. AUC 수치가 커지려면 FPR이 작은 상태에서 얼마나 큰 TPR을 얻을 수 있느냐가 관건이다. 보통의 분류는 가운데 대각선 직선의 AUC 값인 0.5 이상의 값을 가진다.
사이킷런에서는 AUC 을 측정하는 API로 roc_auc_score()를 제공한다.
Comments