
[sklearn] GridSearchCV
27 Mar 2020 | Scikit--Learn하이퍼 파라미터를 순차적으로 적용하면서 최고 성능을 가지는 파라미터 조합을 찾을 수 있다.
grid_parameters = {'max_depth':[1,2,3], 'min_sample_split':[2,3]}
하이퍼 파라미터는 순차적으로 적용이 되며 순서는 (1,2), (1,3), (2,2), (2,3) … 순으로 진행된다. 총 6회에 걸쳐 실행하면서 최적의 파라미터와 수행 결과를 도출할 수 있다. for 루프를 이용하여 사용자가 직접 모든 파라미터를 번갈아 입력하는 대신에 조금 더 유연하게 API 레벨에서 제공한 것이다.
GridSearchCV는 cross-validation을 기반으로 최적 값을 찾아준다. 즉, 데이터 세트를 cross-validation을 위한 학습/데이터 세트로 자동 분할 후 파라미터를 순차적으로 적용해간다. GridSearchCV는 편리한 대신 수행시간이 상대적으로 오래 걸린다.
위의 예제 코드와 같은 경우, CV가 3이라면 6회×3회 = 총 18회의 학습/평가가 이뤄진다. GridSearchCV 클래스의 생성자로 들어가는 주요 파라미터는 다음과 같다.
- estimator : classifier, regressor, pipeline이 사용될 수 있다.
- param_grid : 파라미터 딕셔너리. (파라미터명과 사용될 여러 파라미터 값을 지정)
- scoring : 예측 성능을 측정할 평가 방법. 보통은 사이킷런에서 제공하는 문자열 (예: ‘accuracy’)을 넣지만 별도의 함수도 직접 지정이 가능하다.
- cv : 교차 검증을 위해 분할되는 폴드 수.
- refit : True면 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습시킨다. (default:True)
[예제]
DecisionTreeClassifier의 중요 하이퍼 파라미터인 max_depth와 min_samples_split 값을 찾아본다.
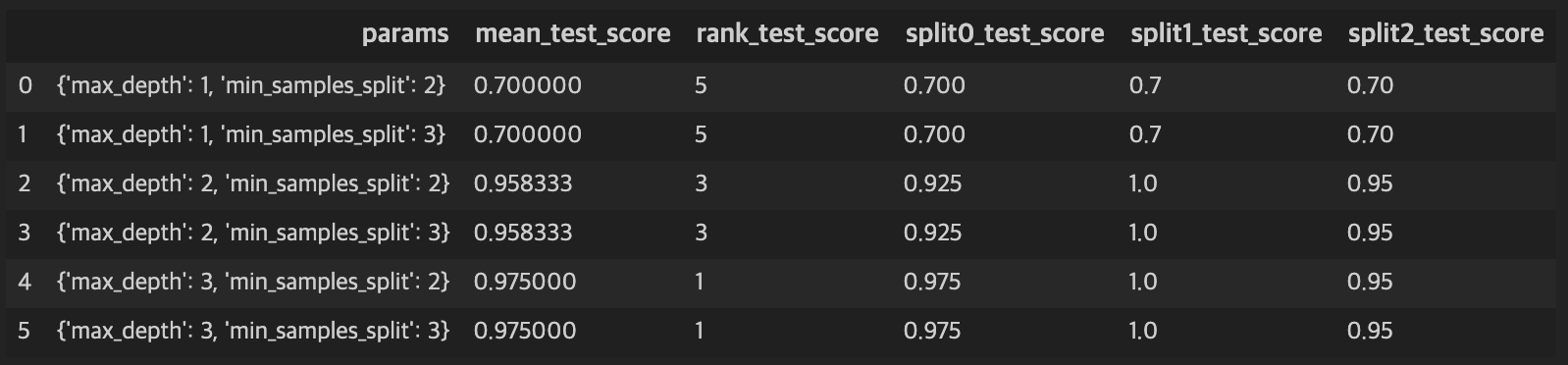
결과는 cv_results_에 저장된다. 결과에서 rank_test_score가 성능의 순위를 나타낸다. 즉, max_depth:3, min_samples_split:2 로 평가한 결과가 성능이 1위이다. 그 밑줄인 index 5도 rank가 1로 공동1위란 의미이다. split\(N\)_test_score은 각 폴드 세트 \(N\)번째에서의 성능 수치이고 mean_test_score은 3개 성능 수치를 평균화한 것이다.
GridSearchCV 객체의 fit( )을 수행하면 최고 성능일 때의 하이퍼 파라미터값과 그때의 평가 결과 값이 각각 best_params_, best_score_ 속성에 기록된다.

dfdf
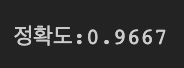
refit=True 상태이므로 최적 성능을 보여주는 파라미터로 학습된 estimator는 best_estimator_로 저장되어 있다. 저장된 best estimator로 처음에 나눴던 테스트 데이터셋에 대해 테스트를 진행한다.
Comments