
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
20 Sep 2020 | Semi-supervised GoogleKihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Han Zhang, Colin Raffel
[Google Research]
[Submitted on 21 Jan 2020]
arXiv:2001.07685

소량의 labeled data를 사용하는 semi-supervised learning 에 관련된 논문이다. 두 가지 semi-supervised 방식을 활용하는데 consistency regularization과 pseudo-labeling을 사용한다. Consistency regularization은 하나의 같은 image를 변형해도 비슷한 representation을 가진다는 점을 이용하고 pseudo labeling은 unlabeld data에 대해 인공으로 뽑아낸 label을 사용한다.
메인 아이디어는 아주 적은 양의 labeled data로 모델을 학습시키고 unlabeld image에 대하여 weakly-augmented를 적용하여 모델에 넣는다. 그렇게 얻어낸 prediction에서 pseudo-label을 뽑아내고 다시 같은 이미지에 대해 strongly-augmented를 적용하여 얻어낸 prediction과 앞서 얻어낸 pseudo-label이 비슷하도록 학습을 시킨다.
FixMatch
FixMatch 설명에 앞서 정의를 정리해보자.
- \(X = \{(x_b, p_b) : b \in (1, ..., B)\}\)
- a batch of \(B\) labeled examples, 여기서 \(x_b\)는 training example이고 \(p_b\)는 one-hot label이다.
- \(U = \{u_b : b \in (1, ..., \mu B)\}\)
- a batch of \(\mu B\) unlabeled examples, 여기서 \(\mu\)sms \(X\)와 \(U\) 사이의 상대적 크기를 결정하는 하이퍼파라미터이다.
- \(p_m(y | x)\)
- input x를 모델에 넣었을 때 나오는 predicted class distribution이다.
- \(H(p,q)\)
- 두 확률분포 p와 q 사이의 cross-entropy를 의미한다.
- \(A(·), \alpha(·)\)
- 순서대로 strong, weak augmentation을 의미한다.
Consistency regularization
unlabeled data에 서로 다른 버전의 augmentation들을 이용해도 결국 prediction은 동일하다는 점을 이용한다. Loss function은 아래와 같이 표현한다.

\(\alpha\)와 \(p_m\)은 stochastic function이기 때문에 위 식의 2개의 term은 서로 다른 값을 가지게 된다.
Pseudo-labeling
unlabeled data에 대해 인공적인 label을 얻어 사용하는 것이다. 대부분 “hard” label을 사용하고 미리 정의된 threshold보다 큰 확률을 가지는 class만 사용하여 인공적인 label을 뽑아낸다. \(q_b = p_m(y|u_b)\)라고 하고 loss를 정의하면 아래와 같다.

여기서 \(\hat{q_b} = argmax(q_b)\)이고 \(\tau\)는 threshold hyperparameter이다. argmax를 사용한다는 것은 hard label을 사용한다는 것과 동일한 의미를 가지는데 이는 entropy minimization과 관련이 있다. 즉, unlabeled data에 대한 모델의 예측이 low-entropy(=high confidence)를 가지게 한다.
FixMatch Loss
FixMatch를 위한 loss function은 2개의 cross-entropy loss텀으로 이루어져있다.
supervised loss \(l_s\)는 labeled example에 weakly augmentation을 적용한 것으로 아래와 같이 나타낸다.
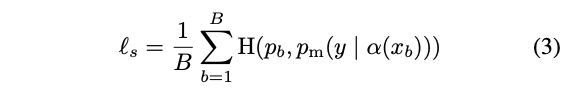
반면 unlabeled data에 대해서는 인공 label을 각각의 example에 대해서 계산한 후 cross-entropy에 적용한다.

인공 label을 얻기위해 가장먼저 unlabeled image에 대해 weakly augmentation을 적용하고 predicted class distribution을 계산한다 : \(q_b = p_m(y \lvert \alpha(u_b))\). 이렇게 얻은 distribution에 바로 argmax를 적용하여 pseudo-label을 얻어낸다 : \(\hat{q_b} = argmax(q_b)\). 마지막으로 이렇게 얻어낸 pseudo label과 strongly-augmented unlabeled image \(u_b\)의 output이 비슷해지도록 cross-entropy를 계산한다.
위에서 \(\tau\)는 pseudo label만들 때 사용되는 threshold hyperparameter이다.
최종적으로 FixMatch의 loss 는 \(l_s + \lambda_u l_u\)이다. 이 때 \(\lambda_u\)는 unlabeled loss의 weight을 결정하는 scalar hyperparameter이다.
사실 위의 (4)식은 앞서 봤던 (2)식의 pseudo-labeling loss와 유사한데 가장 중요한 차이점은 label이 weakly-augmented image를 기반으로 계산되어 strongly-augmented image의 아웃풋과 비슷해지도록 학습이 된다는 점이다. 이는 다시 consistency regularization의 한 형태라고 볼 수 있다.
Augmentation
- Weak : flip & shift
- flip의 경우 horizontal flip으로 prob은 0.5로 준다. 또한 translate는 12.5%로 수평,수직 방향 모두 움직인다.
- Strong : AutoAugment 사용 (그 중 RandAugment or CTAugment)
- AutoAug 적용 후에는 Cutout을 다시 적용함.
RandAugment
RandAugment는 왜곡의 정도를 결정하는 하나의 fixed global magnitude hyperparameter를 사용한다. 이 magnitude값은 validation set에 대해서 최적화되어야 하지만 저자들은 semi-supervised에서는 고정된 하나의 magnitude값을 사용하는 것보다 매 training step마다 미리 정의된 범위안에서 랜덤하게 샘플링하여 사용하는 것이 더 성능이 좋았다고 한다.
CTAugment
변형의 정도를 결정하는 magnitude의 매우 넓은 범위를 bin들로 나눈다. 그리고 각 bin들에 대해 weight이 할당되는데 초기에는 모두 1을 가진다. 그러고는 이 weight값에 따라 확률을 가지며 랜덤하게 샘플링이 된다. 이 weight값은 학습도중에 update가 된다.
Experiments
FixMatch는 극도로 label의 수가 적은 상황에서도 실험을 한다.
CIFAR-10, CIFAR-100, SVHN

labeled data의 5개의 다른 folds를 학습할 때 mean과 variance를 측정한다.
위 표에서 볼 수 있듯이 CIFAR-100에서 ReMixMatch보다 성능이 구렸는데 모델이 모든 클래스에 대해 동일한 확률을 방출하도록 하는 Distribution Alignment (DA)를 적용하면 성능이 굉장히 좋아진다는 것을 발견했다. FixMatch에 DA를 적용했을 때 CIFAR-100 400 labels에서의 성능은 40.14%로 ReMixMatch의 44.28%보다 좋은 성능을 보인다.
그리고 CTAugment와 RandAugmnet의 성능은 비슷비슷했는데 label의 수가 적은 4 labels per class와 같은 경우에는 비슷하지 않았다. 아마도 하나의 클래스를 나타내는 이미지의 수가 엄청 적기 때문에 fold간 분산이 매우 커져 이러한 영향이 발생한 것으로 예상한다.
STL-10

Barely Supervised Learning
FixMatch의 한계를 테스트해보기 위해서 CIFAR-10 데이터셋에 대해 클래스당 오직 하나의 example을 가지도록 설정한 후 실험을 진행했다.
클래스 당 하나의 이미지만을 랜덤하게 선택해서 4개의 데이터셋을 만들고 각각의 데이터셋에 대해 4번씩 실험을 돌렸다. 이렇게 실험을 했을 때는 48.58%~85.32%의 성능을 보였다 (중앙값 64.28%). 데이터 내 variance는 훨씬 더 적었는데 첫번째 데이터셋에서 4개번 돌렸을 때는 61%~67% 이었고 두번째 데이터셋은 68%~75% 성능을 가졌다.
이러한 variability의 원인으로 저자들은 labeled example의 퀄리티를 제안했다. low-quality 이미지들은 모델의 학습을 더욱 더 어렵게 만들기 때문이다. 이것을 테스하기 위해서 또 다시 어떠한 실험을 통해 각 클래스를 제일 잘 나타낼 수 있는 대표 이미지들을 뽑아 실험을 돌렸을 때 중앙값은 78% 성능을 달할 수 있었다.
위에서 언급한 대표 이미지들은 아래의 이미지들을 포함한다.

Ablation Study
추가적인 실험으로 이들은 pseudo-labeing을 진행할 때 sharpening 과 thresholding의 영향을 알아보고 augmentation에서 cutout이 성능을 올리는 데 중요하다는 것 등을 알아냈다.
따로 정리는 하지 않을 계획이다.
다 읽고..
본 논문에서는 consistency regularization과 pseudo-labeling의 조합을 통해 높은 성능의 semi-supervised 기법인 FixMatch를 제안한다. 또한 weakly-augmented labeled 이미지로 supervised learning을 진행하면서 weakly-augmented unlabeled 이미지에서 뽑은 pseudo-label과 strongly-augmented unlabeled 이미지의 predicted distribution 이 비슷해지도록 하는 것이 key element 였다.
사실 평소에 labeled를 전혀 사용하지 않는 self-supervised learning 기법만 연구를 해왔었는데 어느정도 요즘 널리 쓰이는 contrastive learning과 비슷한 감이 있어보인다.
Comments