
Generative Pretraining from Pixels V2 (Image GPT)
07 Sep 2020 | SSL Transformer OpenAIMark Chen, Alec Radford, Rewon Child, Jeff Wu, Heewoo Jun, Prafulla Dhariwal, David Luan, Ilya Sutskever
[OpenAI]
June 17, 2020
Image GPT blog
본 논문에서 사용하고 있는 transformer는 자연어처리에서 많이 사용되는 아키텍처이다. 사실 자연어처리는 아는 지식이 없어 본 논문에서 제안하는 모든 구조를 완벽히 이해하지는 못했지만 어느정도는 이해할 수 있었고 이미지를 하나의 연속적인 sequence로 다룬다는 점이 신선했다.
자연어 처리에서 문장을 하나의 sequence로 input을 주듯이 본 논문에서는 이미지를 픽셀로 줄세워 하나의 sequence로 만든 후 transformer에 input으로 넣는 구조이다.
Introduction
Image GPT의 영감은 자연어 처리에서 왔다고 한다. 언어처럼 이미지 픽셀들을 한 줄로 쫙 피고 sequence Transformer를 학습하여 auto-regressive하게 다음 픽셀을 예측하거나 마스킹된 픽셀 부분의 값을 찾도록(BERT) 하는 구조이다. 이러한 generative pre-training은 low-resolution의 데이터에서 굉장히 좋은 성능을 보인다.
이들은 이미지의 2D spatial structure를 인코딩하지 않는 dense connectivity pattern을 사용하지만 그럼에도 불구하고 2D spatial structure를 인코딩하는 (ex. CNN) 모델들과 성능이 거의 유사하거나 오히려 뛰어난 실험도 존재했다. 물론 뒤에서 볼 수 있듯이 high-resolution에는 크게 좋은 성능을 보이지는 않지만 low-resolution에는 좋은 성능을 보이고 있다.
Approach
Self-supervised 방식으로 모델을 학습시키기 위해서 이들은 2가지 objective를 사용한다: auto-regressive and BERT.
1.우선 모델에 넣기 전 raw image를 low resolution으로 리사이징 후 1D sequence로 모양을 바꿔준다.

2.그 다음 두 가지 objective중 하나를 택한다.
- Auto-regressive의 경우 이전의 픽셀 정보들을 사용하여 다음에 올 픽셀을 예측하는 방식이다. == \(L_{AR}\)
- BERT는 input sequence에 픽셀들을 마스킹하고 마스킹된 부분들의 값을 찾기 위해서 앞뒤의 픽셀정보를 모두 이용하는 방식이다. == \(L_{BERT}\)
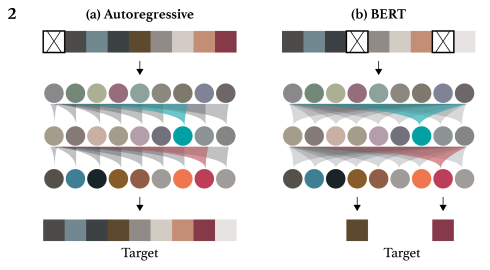
3.이렇게 학습이 완료된 모델을 가지고 linear probing이나 finetuning을 통해 성능을 확인한다.
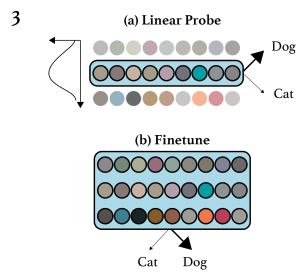
Fine-tuning
Fine-tuning시에는 마지막 단의 sequence dimension을 average pooling하여 class logit을 뽑아내고 이 class logit들을 cross entropy loss를 최소화하는데 사용한다. == \(L_{CLF}\)
물론 \(L_{CLF}\)를 줄이는 것만해도 봐줄만한 성능이 나오지만 generative training을 함께 학습하는 joint objective를 줄이도록 하면 더 좋은 성능을 보인다고 한다.
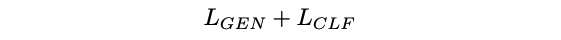
여기서 \(L_{GEN} \in \{L_{AR}, L_{BERT}\}\) 이다.
Linear Probing
Linear probing에서는 제일 끝단의 feature를 사용하지 않는다. 제일 좋은 성능을 보이는 feature들은 네트워크의 중간에 존재한다는 것을 실험을 통해 밝혀냈기 때문이다. 때문에 이 중간의 feature를 사용하여 class logit을 생성한다.
또한 linear probing에서는 학습되어 있는 모델이 fixed되어 있다고 생각하기 때문에 fine-tuning에서와 다르게 joint하지 않고 \(L_{CLF}\)만 최적화한다.
Methodology
Dataset and Data Augmentation
ImageNet ILSVRC 2012 training dataset에서 4%는 validation set으로 사용하고 원래 validation set을 test set으로 사용한다. CIFAR-10, CIFAR-100, STL-10과 같은 작은 데이터셋은 10%를 validation으로 사용한다.
Web image들에 대해서 pre-training 시킬 때에는 DA를 적용하지 않았고 ImageNet에 대해 pre-training이나 fine-tuning할 때는 가벼운 DA(resize&crop)를 적용했다. CIFAR 데이터셋에 fine-tuning할 때는 padding 후 crop이나 horizontal flip과 같은 조금 더 다양한 DA를 적용하기도 했다.
앞서 위에서 떼어낸 validation set들은 최적의 하이퍼파라미터가 찾아지면 다시 training set에 넣어져 모두 학습이 가능하도록 했다.
Context Reduction
사실 나는 transformer의 구조를 잘 모르기 때문에 얼마만큼의 메모리가 필요로 한지는 정확히 모른다. 하지만 저자들은 transformer decoder를 위한 메모리가 dese attention을 이용하면 context length에 따라서 quadratical하게 증가한다고 한다. 단순히 생각해보면 224×224×3 사이즈의 이미지를 sequence로 만들어 넣으면 attention logit은 굉장히 길어지게 된다. 이는 너무 부담스럽기 때문에 저자들은 이미지를 lower resolution으로 변경하도록 한다. 이러한 이미지 resolution을 input resolution (IR)라고 부른다. 따라서 이들 모델은 \(32^2 × 3, 48^2 × 3, 64^2 × 3\)라는 IR을 가진다.
근데 또 다시 \(32^2 × 3\)를 보면 여전히 꽤나 큰 수임을 알 수 있다. 그래서 또 한 번 크기를 줄이기 위해서 9-bit color palette를 만든다. 이는 (R, G, B) 픽셀 값들을 k-means 방식을 통해 (k=512) 클러스터링하여 생성했다. 이렇게 되면 RGB 채널을 하나로 보기 때문에 context length를 3배 줄일 수 있고 색들에도 변화가 거의 없게 된다 (원본 이미지 충분히 표현 가능). 이 context length를 model resolution (MR)이라고 부르고 \(32^2, 48^2, 64^2\)가 존재한다.
Model & Training
model은 크기에 따라서 iGPT-XL, iGPT-L, iGPT-M, iGPT-S (갈수록 작아짐)으로 구분한다.
XL을 학습시킬 때는 64 배치 사이즈를 사용했고 2M iteration을 돌렸다. 다른 모델들은 128/1M iteration을 돌렸다. Early stopping을 사용하였으며 dropout은 사용하지 않았다.
실험마다 차이가 있으니 직접 읽는 것을 추천한다.
Experiments and Results
마지막 BERT를 실험한 부분을 제외하고 나머지 실험들은 더 나은 성능을 보여준 auto-regressive 방식에 대해 진행되었다.
What Representation Works Best in a Generative Model Without Latent Variables?
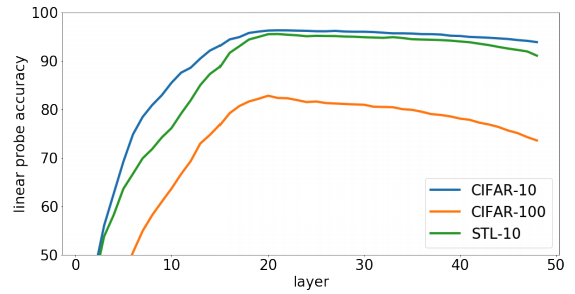
Supervised pre-training에서는 대부분 끝에서 두 번째 layer가 best quality representation을 가진다고 한다. 근데 사실 generative pre-training의 경우 다음 픽셀을 예측하는 태스크가 이미지 classification task와 관련이 있는지 명확하지 않다. 즉, 이 경우는 끝에서 두 번째 layer에 제일 좋은 representation이 있을지는 확신할 수 없다는 것이다. 그래서 그냥 모든 layer마다 확인을 해봤다.
위의 그림에서 알 수 있듯이 representation은 점점 성능이 증가하다가 중간층에 와서는 다시 떨어지기 시작한다. 그래서 저자들은 generative model을 linear probe으로 평가하기 위해서는 best layer를 찾는 것이 중요하다고 주장한다.
Better Generative Models Learn Better Representations
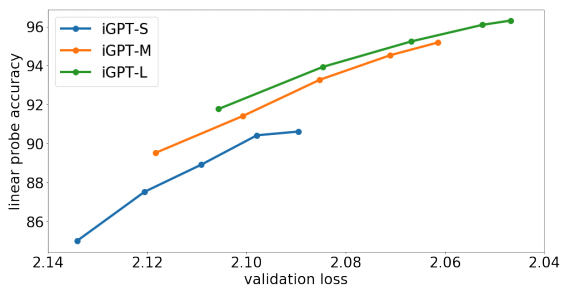
위 그림에서 볼 수 있듯이, training 때 validation 성능이 높은 애가 더 좋은 linear probe 성능을 보인다. 또한 더 높은 capacity를 가진 model (=더 큰 모델)이 더 좋은 validation 성능을 보였고 linear probe 결과 또한 동일했다. 즉, 큰 모델을 사용하는 것이 중요하다는 것이다.
Linear Probes on CIFAR and STL-10
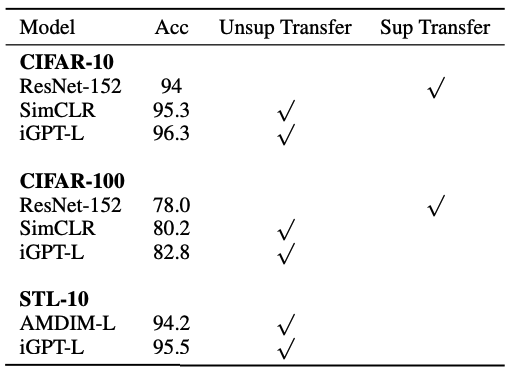
ImageNet에 대해 pre-trained 시킨 후 여러 다른 데이터셋에 linear probe 평가를 시행한 경우 최고 수준을 보였다.
Linear Probes on ImageNet
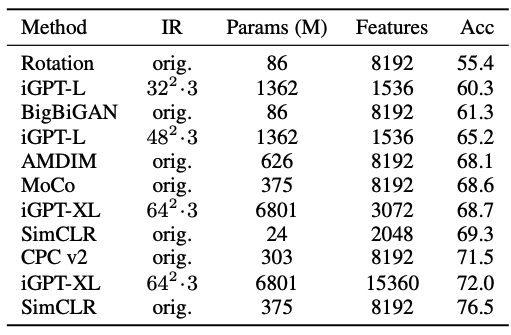
ImageNet에 대해서도 linear probe 평가를 시행했다. 사실 이 실험은 해당 모델이 표준 ImageNet IR에 효과적으로 학습이 불가능하기 때문에 어려운 부분이 있었다고 한다.
그러나 모델의 크기를 늘리고 MR을 크게할수록 성능도 올라가긴 한다. 표에서 밑에서 두 번째의 iGPT-XL 실험의 경우 다수의 layer로부터 얻은 feature들을 concat하여 실험한 결과이다. 저자들은 이 성능이 SimCLR과 견줄만하다고 말하지만 사실상 내 눈에는 더 많은 param과 feature를 사용했음에도 성능이 4프로나 낮기 때문에 그닥 좋은 방법은 아닌 것 같다. 즉, 본 논문의 방식은 low resolution에서만 잘 작동하는 것 같다.
Full Fine-tuning
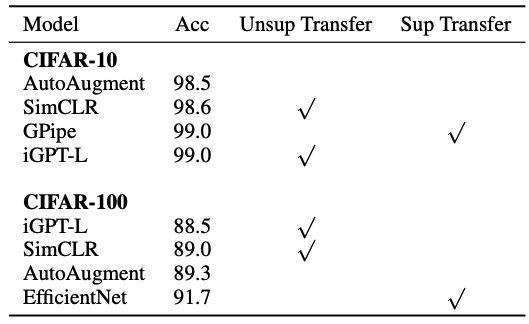
저자들은 linear probing과 같이 가장 좋은 representation을 가지는 중간 layer에 classification head를 달려고 시도했다. 이 위치는 마지막 layer에 붙이는 것보다 더 빠른 학습을 할 수 있지만 마지막 layer에 head를 부착하는 것이 더 큰 모델 depth를 이용할 수 있어 결과적으로 더 우수한 성능을 보였다고 한다.
CIFAR-10에서는 어떠한 세련된 DA를 사용하지 않고도 image GPT가 AutoAugment보다 높은 성능을 보였다. Fine-tuning 실험은 더 작은 데이터셋에 대해 진행이 되므로 overfitting이 일어날 수 있어 validation accuracy 를 기준으로 early stopping을 사용했다.
BERT
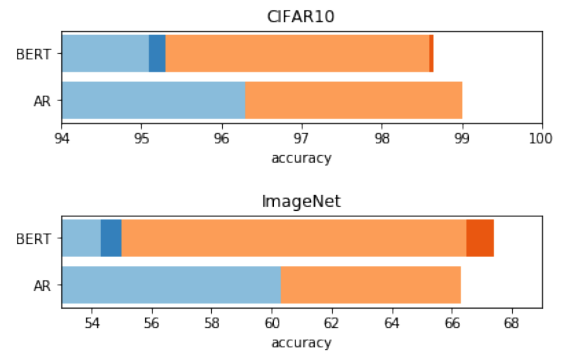
위 그림에서 파란색은 linear probe, 주황색은 fine-tuning의 성능을 의미한다. 더 진한 색은 BERT mask를 앙상블하여 성능을 높인 경우이다.
BERT objective를 사용하여 학습한 경우는 조금 특이했다. \(32^2 × 3\) IR과 \(32^2\) MR을 사용하는데 CIFAR-10에 대하여 linear probe한 결과는 auto-regressive보다 낮았다. 근데 또 fine-tuning을 하면 어느정도 AR의 성능을 따라 잡는 것을 볼 수 있다. 심지어 ImageNet에 대해서는 아주 조금이지만 BERT가 더 높았다. High resolution에 대해서는 BERT가 더 나은 성능을 보인다.
BERT 모델 사용 시, training time 뿐만 아니라 evaluation time에도 masking을 해야 input in-distribution을 유지할 수 있다. 하지만 이러한 마스킹이 성능을 해치는 부분이 있을 수 있어 저자들은 5개의 독립적인 mask를 생성하여 테스트 후 앙상블을 했다. 그 결과가 위의 그림에서 진하게 나온 BERT mask ensemble이다. BERT mask ensemble은 CIFAR-10에서는 큰 효과를 얻지 못했지만 ImageNet에서는 거의 1%나 성능을 높일 수 있었다.
다 읽고..
저자들은 기존 NLP에서 사용하던 transformer를 이미지에 적용하여 low-resolution 데이터에 대해 좋은 성능을 얻어냈다. 이미지를 1D sequence로 펼쳐서 언어 sentece와 같은 형태로 사용했다는 것이 재미있는 포인트였다. 근데 단지 다음 픽셀을 예측하는 것만으로도 이 정도 성능을 배울 수 있었다는 점은 아직은 이해가 잘 되지 않는다. 이미지에서 아주 작은 픽셀을 이용하는 것은 이미지의 2d spatial 정보도 사용하지 않는데 어떻게 이러한 좋은 성능이 나왔는지 신기하다.
Comments