
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning (BYOL)
12 Aug 2020 | SSL GoogleJean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
[DeepMind]
Submitted on 13 Jun 2020
arXiv:2006.07733
현재 semi-supervised 기법을 이용하는 SimCLR v2를 제외한다면 SOTA 인 BYOL에 대한 논문이다.
SimCLR과 가장 큰 차이를 고르라면 negative examples들을 사용하지 않는다는 것? 그리고 다른 네트워크 (target net.)을 업데이트하기 위해서 또 다른 네트워크의 slow-moving average(=slowly moving exponential average)를 이용한다는 것이 좀 신선했다.
Comparison
앞서 먼저 리뷰했었던 SimCLR은 semi-supervised 방식(v2)을 활용하여 현재 SOTA image classification 점수를 유지하고 있다. 그러나 완전한 self-supervised 방식인 SimCLR v1 방식을 살펴보자. SimCLR은 엄청난 양의 negative sampless들과의 contrastive learning을 통해 성능을 매우 높였다. 하지만 이러한 SimCLR에도 단점이 존재한다.
- negative pairs 처리에 있어 신중해야 한다 : large batch size, memory bank, customized mining strategy 등에 의존적이다.
- Data augmentation 선택이 성능에 매우 critical 영향을 준다.
이러한 단점을 극복해내려는 듯이 BYOL은 negatives 를 사용하지 않고도 더 좋은 성능을 보인다. 또한 negative samples을 사용하지 않음으로써 오히려 data augmentation 선택에 더 robust 해졌다.
Main Idea
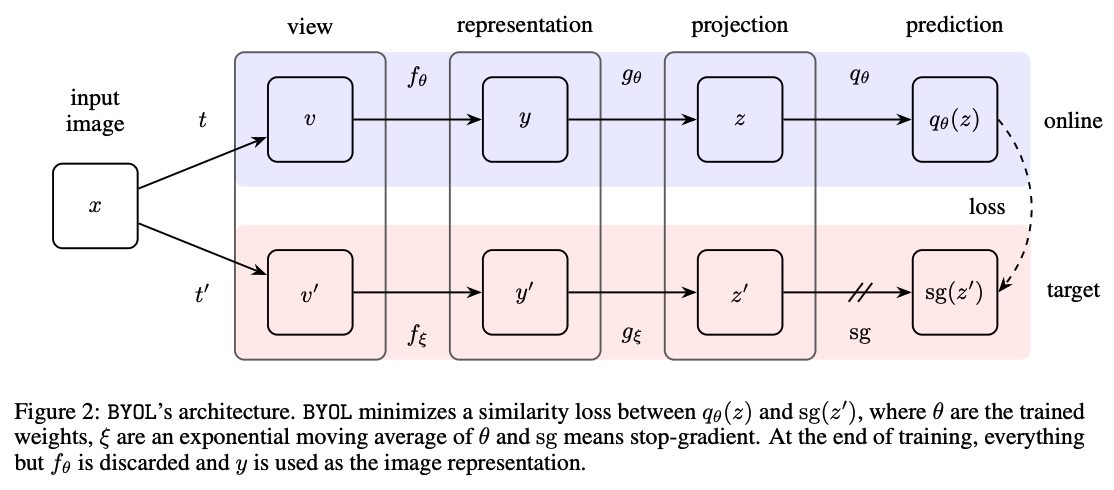
BYOL의 전체적인 구조는 위와 같이 생겼다.
BYOL은 2개의 네트워크로 구성되어 있다.
- target representation을 뽑아내는 target network
- target의 prediction을 뽑아내는 online network
각 네트워크는 encoder \(f\), projector \(g\), predictor \(q\) 단계로 구성되어 있다.
여기서 \(f\)는 일반 conv net (resnet)이며 \(g\)와 \(q\)는 MLP으로 구성되어 있다. \(g\)와 \(q\)를 사용해서 차원을 줄인다.
이 때 online network는 target network 에서 생성하는 representation을 예측하도록 학습이 되며 target 네트워크의 파라미터 업데이트는 online의 exponential moving average를 사용하기 때문에 stop gradient(sg)라고 표현되어 있다.
BYOL의 목표는 downstream task에서 사용될 representation y를 학습하는 것이다.
잠시 BYOL이 나오게 된 계기를 살펴본다.
많은 성공적인 SSL 기법들은 (읽어보지는 않았지만..) 제프리 힌턴 교수의 논문 Self-organizing neural network that discovers surfaces in random-dot stereograms에서 나온 cross-view prediction framework를 베이스로 만들어졌다고 한다.
해당 논문에서는 같은 이미지로부터 얻은 다른 view 를 예측하도록 하는데 이 때 단점은 representation space에서 직접 예측을 하기 때문에 collapsed representation을 학습할 수도 있다는 점이다. 예를 들면, 모든 view에서 일관적인 representation은 항상 그 자체를 바로 예상할 수 있다는 점이다.
이러한 collapsed representation 학습을 피하기 위해서 contrastive learning은 cross-view prediction을 하나의 discrimination 문제로 재정의하여 학습하도록 한다. 즉, 같은 이미지의 서로 다른 DA를 통해 얻은 patch들과 다른 이미지들을 통해 얻은 patch들을 구분하는 문제로 바꿨다는 것이다. 하지만 이를 위해서는 수많은 negatives 들과 비교를 해야한다는 단점이 존재한다.
이 때문에 구글팀은 ‘과연 높은 성능을 유지하면서 collapsing을 막기 위해서는 이러한 많은 negatives들이 필수적인가?’ 라는 의문을 품게 된다.
Collapsing을 피하기 위해서 간단한 실험을 한다.
① 우선 두 개의 네트워크를 임의로 초기화를 시켜준다.

②그렇게 랜덤하게 초기화된 네트워크 하나(파란색)에 linear layer를 맨 뒤에 추가해주고 ImageNet dataset에 대해서 학습을 진행한다. == 끝의 linear layer만 학습이 되는 중.

이렇게 학습을 시켰을 때는 당연히 성능이 낮게 나온다. (1.4%)
③ 위에서 학습한 파란색 네트워크를 마지막 층까지 얼려놓고 (학습 업데이트를 전혀하지 않고 feature extractor로 사용) unlabeled data를 넣어 output을 뽑아낸다. (아래 그림 중 윗부분)
④ 얼린 파란색 네트워크에서 뽑아낸 output을 임의의 target label로 잡고 다시 초록색 네트워크를 얼린 채 unlabeled data를 학습시킨다. 즉 초록색 네트워크는 ground truth label이 아닌 파란색 네트워크가 정답일 것이라 예측하는 representation을 label 삼아 학습을 진행한다. 하지만 놀랍게도 성능은 18.8%나 된다. (아래 그림 중 아랫부분)
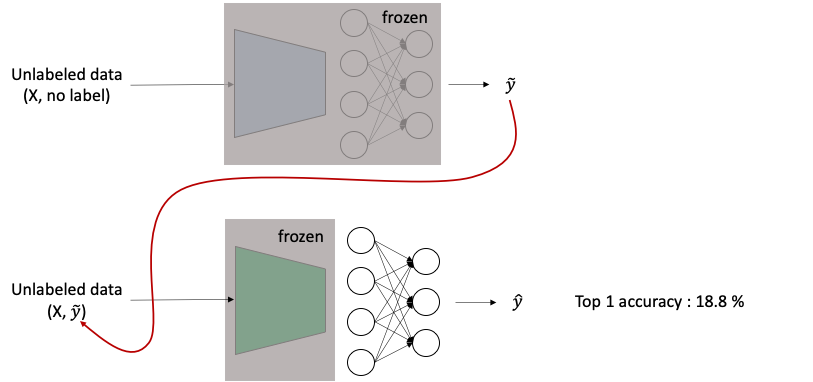
위의 실험은 BYOL의 핵심 동기가 된다 : 네트워크의 아주 작은 부분을 데이터에 대해 학습시켰고 학습된 네트워크로 뽑아낸 임의의 representation을 target으로 삼아 또 다른 random initialize된 네트워크는 더 좋은 representation을 배웠다.
즉, target이라고 하는 주어진 representation으로부터 online이라고 하는 새롭고 더 잠재적으로 향상된 representation을 얻을 수 있다는 것이다.
Description
Exponential Moving Average
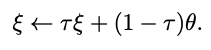
target network의 파라미터는 \(\xi\) 로 나타내고 online network의 파라미터는 \(\theta\)로 나타낸다.
이 때 \(\xi\)는 \(\theta\) exponential moving average로 구한다. 즉, target network의 파라미터들은 계속해서 변하는 online network 파라미터들을 통해 평균적으로 움직이면서 구해지게 된다.
Target decay rate \(\tau\)는 0과 1사이의 값으로 정하는데 이 값은 exponential moving average에서 이전의 \(\xi\)를 얼만큼 반영할 것인지를 결정한다고 생각하면 된다. 반대로 현재 online network 파라미터를 얼마나 반영할지도 정하게 된다.
무튼 위 식을 통해 training step 마다 업데이트된다.
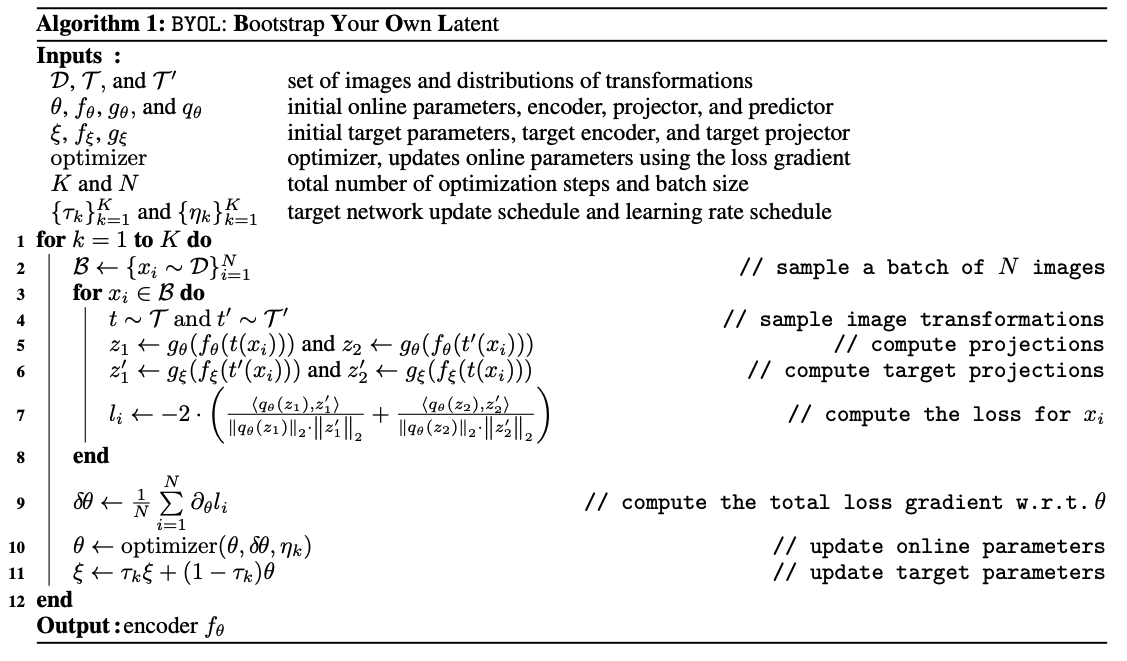
아래의 알고리즘을 보면 더 쉽게 이해가 될 것이다.
Loss Fucntion
loss function 정의에 대해서는 설명이 지문에 그대로 적혀있어서 그냥 긁어왔다..ㅎ
SimCLR에서 positive pairs를 서로 비슷하게 만드는 것과 유사하다.

무튼 위의 식은 \(v\)를 online net.에 넣고 \(v'\)을 target net.에 넣었을 때의 loss \(L^{BYOL}_\theta\)이다.
반대로 \(v'\)를 online net.에 넣고 \(v\)을 target net.에 넣었을 때의 loss를 \(\tilde{L}^{BYOL}_\theta\)라 한다.
최종적인 loss는 \(L^{BYOL}_\theta + \tilde{L}^{BYOL}_\theta\) 이다.
Experiments
생략…
Ablation
Batch size
앞서 BYOL은 negative example들을 사용하지 않기 때문에 batch size에 조금 더 robust한 경향을 보일 것이라 저자들은 예상했다. 그래서 이를 실험적으로 밝혀내기 위해 batch size를 128에서 4096까지 늘려가며 실험을 했다.
하이퍼 파라미터를 다시 튜닝하는 번거로움을 피하기 위해 batch size를 \(\frac{1}{N}\) 로 줄일 때마다 online net을 업데이트 하기 위해서 \(N\) epoch을 학습 후 gradient를 평균내서 업데이트를 한다. 이렇게 하면 한 번 업데이트에 사용되는 샘플 수가 유지될 수 있어서 이 방식을 사용하는 것 같다.
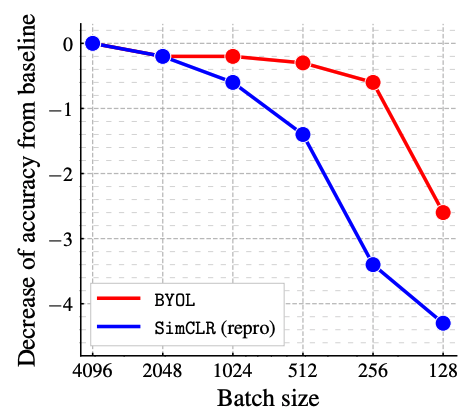
파란색인 SimCLR은 역시나 비교할 negative들의 수가 줄어드니까 성능도 줄어들었다.
BYOL은 나름안정적이었는데 조금씩 떨어지는 drop은 encoder에서 사용되는 BN layer에서 발생하는 것으로 예측했다. 이 layer만이 BYOL에서 유일하게 batch size에 의존하기 때문이다.
Image augmentation
SimCLR은 color distortion을 없애버리면 잘 작동하지 않는다. 이는 같은 이미지로부터의 crop들이 color histogram을 공유하기 때문에 이 부분에 집중하게 되면서 trivial solution을 풀게 된다. 특히 다른 이미지와의 histogram은 공유하지 않기 때문에 더 쉬워지는 문제가 발생한다. 이렇게 되면 color histogram 이외의 정보는 유지하지 않는 식으로 학습이 진행돼서 representation의 질이 떨어진다.
반면 BYOL은 target representation에 캡처되어 있는 모든 정보를 online network에 보관하도록 학습이 된다. 즉, 같은 이미지로부터의 crop들이 여전히 color histogram을 공유하지만 그 이외의 추가적인 feature들도 유지할 수 있기 때문에 color distortion을 사용하지 않아도 학습이 어느정도 잘 된다는 것이다. 이러한 이유에서 저자들은 BYOL이 DA 선택에 있어 더욱 robust할 것이라 생각했고 이에 대한 실험을 진행했다.
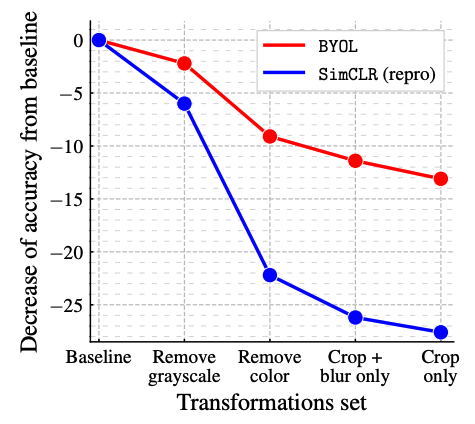
위의 그림에서도 볼 수 있듯이 점점 DA를 없애가면서 실험을 한 뒤 그냥 crop만 남은 상태에서도 BYOL은 큰 drop을 보이지 않았다.
Bootstrapping
BYOL의 target network를 업데이트하는데 사용되는 식에서 target decay rate \(\tau\)의 영향을 알아본다.
- \(\tau=1\) 일 때
- \(\tau \leftarrow \tau\).
- Never updated
- 제일 초기에 random initialize한 상태를 유지한다.
- target이 update 되지 않고 항상 고정되어 있기 때문에 training 자체는 stable하다.
- iterative improvement가 없기 때문에 low-quality final representation을 얻게된다.
- \(\tau=0\) 일 때
- \[\tau \leftarrow \theta\]
- instant update to online at each step
- target이 휙휙 바껴서 training은 unstable하다.
- very poor performance를 보인다.

최적의 \(\tau\)를 찾기 위해서 실험을 진행했을 때 위와 같은 결과를 얻을 수 있었다.
다 읽고..
저자들은 BYOL이 성능 개선을 보였으나 여전히 data augmentation에 의존적이고 심지어 이러한 data augmentation은 vision application에만 한정되어 있다는 점이 한계라고 했다. BYOL을 다른 application (audio, video, text)에 적용하기 위해서 각각에 적절한 augmentation 기법을 얻는 것이 다음 스텝이 될 것이라 했다.
해당 논문을 읽고 약간 궁금한 점이 생겨서 공식적인 코드는 아니지만 다른 사람이 구현한 코드로 돌려보고 있다. contrastive loss를 사용하지 않고도 서로 같은 이미지로부터의 패치들을 학습하면서 성능을 더욱 높일 수 있다는 점은 정말 획기적인 것 같다.
Comments