
Rethinking Pre-training and Self-training
01 Aug 2020 | Self-training Rethinking GoogleBarret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin D. Cubuk, Quoc V. Le
[Google Research, Brain Team]
Submitted on 11 Jun 2020
arXiv:2006.06882
최근에 구글팀에서 발표한 self-training에 대한 rethinking 논문이다. 2018년 Kaiming He는 ‘Rethinking ImageNet Pre-training’ 논문에서 ImageNet pre-training은 완전히 다른 task에 적용되었을 때 효과가 좋지 못함을 보였었다. 특히 COCO object detection 과 같은 데이터셋에서 더욱 효과가 떨어졌다.
본 논문에서는 이러한 pre-training의 한계를 넘어서는 self-training에 대해서 칭찬하는 논문이라고 볼 수 있다.
Main Idea
본 논문에서는 ImageNet의 label을 사용하느냐 안하느냐에 따라 pre-training과 self-training을 완전한 반대(stark contrast)라고 말한다. Self-training의 generality와 flexibility를 3가지 측면에서 보여주려는 것이 이들 논문의 목적이다.
- 강력한 data augmentation (이후 DA)와 더 많은 labeled data의 사용은 pre-training의 가치를 떨어트림.
- pre-training과 달리, self-training은 강력한 DA와 low-data & high-data 에서 항상 좋은 성능을 보임.
- pre-training이 효과적인 상황에서는 self-training은 그 효과보다 더 좋은 성능을 보임.
앞서 언급한 Kaiming He의 논문과 비교했을 때 본 논문에서는 pre-training의 역할을 훨씬 더 상세하게 연구(① 훨씬 강력한 DA 사용; ② 다른 pre-training 방식(supervised and self-supervised) 사용; ③ 각각 다른 pre-trained 체크포인트 퀄리티)를 진행했다.
Methods and Control Factors
Data Augmentation

위의 4가지 방식을 사용하는데 여기서 S1을 제외하고는 모두 He의 논문보다 강력한 DA를 의미한다.
- Flips and Crops : horizontal flip & scale jittering –> random resize with scale (0.8, 1.2) and then crop.
- Augmentation-S3, S4 : Large scale jittering with scale (0.5, 2.0)
Pre-training

scratch로 학습시키는 Rand Init과 2가지의 다른 퀄리티를 가지는 pre-trained 체크포인트를 사용한다.
- ImageNet Init : checkpoint trained with AutoAugment.
- ImageNet++ Init : checkpoint trained with Noisy Student, utilizing an additional 300M unlabeled images.
위에서 사용되는 모델은 EfficientNet-B7인데 이는 ResNet을 사용하는 He의 논문보다 강력한 베이스라인을 사용함을 의미한다.
Self-training
self-training의 방식은 noisy student 기반이며 아래와 같은 알고리즘을 사용한다.
- A teacher model is trained on the labeled data (e.g., COCO dataset).
- The teacher model generates pseudo labels on unlabeled data (e.g., ImageNet dataset).
- A student is trained to optimize the loss on human labels and pseudo labels jointly.
위의 self-training할 때 기존의 loss function은 불안정한 부분이 있다며 본인들이 구현한 loss normalization technique을 선보였는데 사실 정확히 왜 저런 비율로 설정하게 되었는지는 모르겠다. 단순하게 생각하면 \(L_h\)가 커지면 \(L_p\)도 함께 커지게하고 \(L_p\)가 커지면 \(L_p\)를 줄이는 방향으로 normalize 시키는 방식인 것 같다.
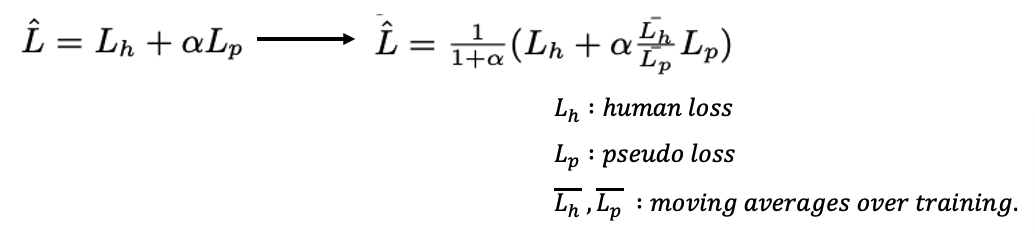
위의 파라미터 ⍺의 경우는 실험을 통해 DA가 강력해질 수록 작아야하고 iteration이 많아질 수록 큰 값으로 설정해줘야한다고 한다.
Experiments
The effects of augmentation and labeled dataset size on pre-training.
Pre-training은 강력한 DA가 사용될 수록 성능을 저하시키고 더 많은 labeled 데이터를 사용해도 성능을 저하시켰다.
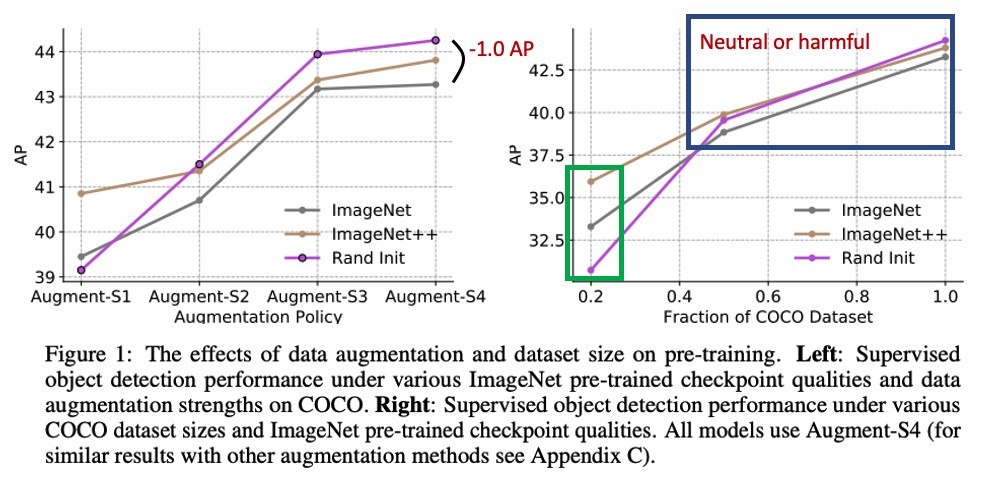
왼쪽 그림에서 보면 더욱 강력한 DA가 사용될 수록 오히려 scratch인 Rand Init의 성능이 더 좋아졌고 오른쪽 그림을 보면 labeled data를 더 많이 사용할 수록 Rand Init과 성능이 비슷하거나 오히려 보다 나빠지는 것을 알 수 있다.
오른쪽 그림의 초록색 칸에서 알 수 있는 점은 low data를 사용할 때는 체크포인트의 퀄리티와 성능이 상관관계를 가진다는 것이다.
The effects of augmentation and labeled dataset size on self-training.
self-training에서는 그런거 상관없이 두 가지 실험에서 모두 다 성능이 향상됐다.

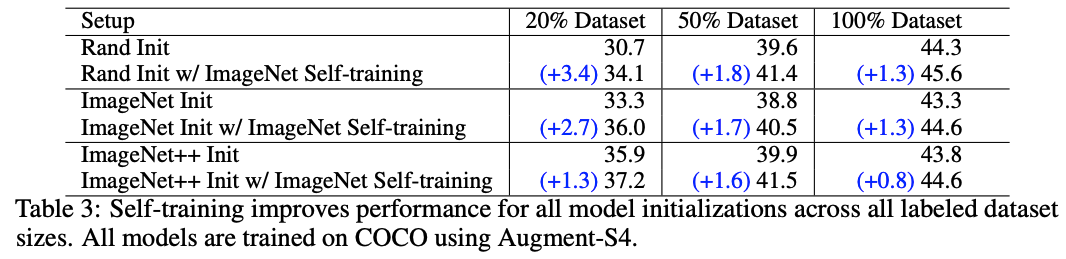
Self-supervised pre-training also hurts when self-training helps in high data/strong augmentation regimes.
이번에는 supervised 방식으로 학습한 pre-training 말고 self-supervised 방식으로 학습된 pre-training을 사용하여 실험했는데 이 또한 많은 labeled 데이터와 강력한 DA에 있어 성능이 좋아지지 않았다.
실험에서 사용된 방법은 최신 SOTA self-supervised learning 기법인 SimCLR을 사용하였는데 역시나 ImageNet 데이터를 사용하여 체크포인트를 만들어내고 그 다음 COCO에 finetuning 시키는 방식으로 진행되었다.
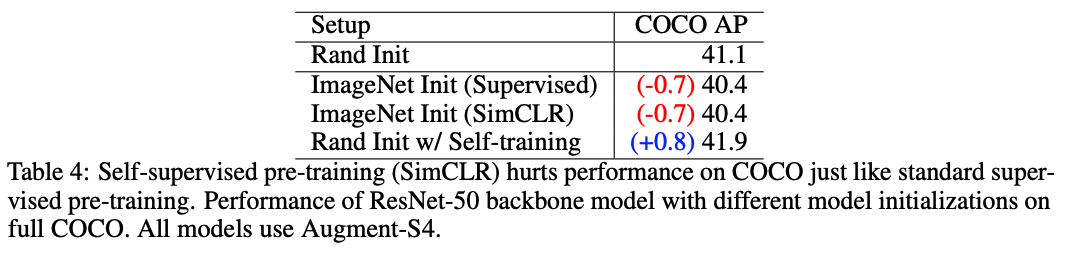
self-supervised와 self-training 모두 이미지의 label을 사용하지 않고 학습을 진행하지만 self-training 방식만이 COCO의 성능을 높이는데 도움이 되었다.
COCO object detection과 PASCAL VOC Semantic Segmentation에 대하여 실험부분도 논문에 존재하지만 이 부분은 따로 블로그에 정리하지는 않겠다.
Discussion
Rethinking pre-training and universal feature representations.
여러가지 실험에서 pre-training이 힘을 제대로 발휘하지 못하는 이유로 저자들은 pre-training이 task of interest를 잘 파악하지 못하기 때문이라고 주장한다. 예를 들어, ImageNet에서 좋았던 feature들은 COCO에서 필요한 위치 정보를 버리는 것과 같은 문제가 존재한다는 것이다.
반면 self-training은 매우 general 하기 때문에 task of interest를 잘 파악한다는 것이다.
대신, 현재의 self-training 방식은 여전히 한계가 존재한다. 특히 pre-trained model을 fine-tuning하는 것보다 더 많은 계산을 해야한다는 점이 그 한계라고 할 수 있다.
다 읽고..
내가 정확히 파악한 것인지는 모르겠으나 어느 정도 두 방식을 비교 대상으로 잡은 것이 과연 올바를까? 하는 의문이 존재한다. 일단 생각하기에는 pre-training의 경우 COCO 데이터 셋에 대해서 단 한 번만 fine-tuning을 진행하는 반면, self-training은 pseudo label과 함께 다시 학습하는 방식으로 여러 번 학습이 진행되니까 여기에서 오는 성능 향상이 조금 있지 않을까 라는 생각도 든다. 그래도 일단 self-training의 computation cost를 줄이는 방법을 연구하는 것도 좋은 연구가 될 수 있을 것이라 생각한다 :)
Comments