
Self-training with Noisy Student improves ImageNet classification
20 Jul 2020 | Semi-supervised Self-training GoogleQizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le
Submitted on 11 Nov 2019 (v1), last revised 19 Jun 2020 (this version, v4)
arXiv:1911.04252
올 초에 읽었던 논문인 Noisy Student. 정리하는 걸 잊은 채로 지내다 얼마전 랩 세미나에서 다른 학생이 발표를 해 생각이 나 정리를 해본다. Teacher model에서 pseudo label을 뽑아내 이를 student model의 learning target이 되도록 하고 학습된 student model은 다시 다른 모델의 teacher 모델이 되고 .. 를 반복하는 형태이다.
작성하고 있는 현재 기준, 지금은 fixEfficientnet가 SOTA인지만 한동안 SOTA였던 만큼 흥미로운 논문이었다. fixEffi는 다음에 시간이 나면 읽어볼 예정이다.
1. Introduction
오직 labeled image를 가지고 model을 학습시키는 것은 수많은 unlabeled image들을 활용하지 못하는 한계를 가지게 된다. 이 논문에서 저자들은 SOTA ImageNet accuracy를 개선시키기 위해 unlabeled image들(JFT-300M)을 사용했고 이러한 성능 향상이 robustness(분포 이외의 일반화)에 엄청난 영향을 미친다는 것을 보여주려한다. 그렇게 하기 위해서 이들은 ImageNet training set의 어느 카테고리에도 속하지 않는 수 많은 unlabeled image를 사용한다.
저자들은 semi-supervised 형태로 teacher와 student model을 학습시킨다.
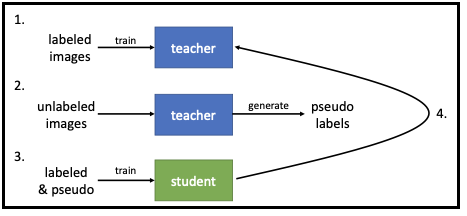
그 당시의 SOTA와 비교를 했을 때 성능표는 이러했다.

2. Noisy Student Training
Noisy Student 알고리즘을 슈도코드로 나타내면 아래와 같다.

이 때 teacher model이 생성하는 pseudo label은 soft할 수도 hard 할 수도 있다. 여기서 soft는 [0.2 0.3 0.4 0.1] 과 같은 확률 값을 의미한다면 hard는 동일한 확률에서 추출해낸 one-hot distribution인 [0 0 1 0] 을 의미한다.
이제 student model은 기존에 가지고 있던 labeled image와 pseudo-label을 뽑아낸 unlabeled image를 결합해서 학습하게 되는 때 이 때 combined cross-entropy loss를 최소화하면 된다.
Comparison with [Knowledge Distillation]
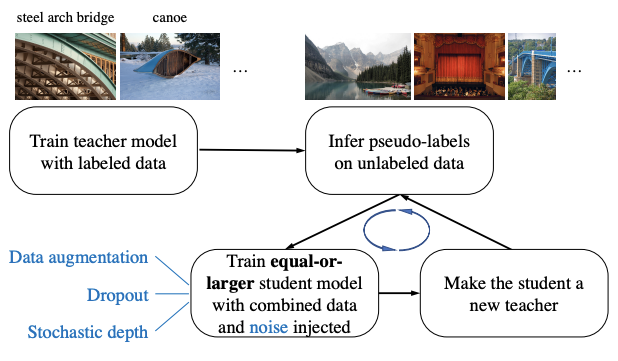
이들은 student에 다양한 noise를 준다는 것과 teacher보다 같거나 오히려 더 큰 student model을 사용했다. 이러한 점이 noise를 추가하는 것이 키포인트가 아니고 더 빠른 학습을 위해 teacher보다 더 작은 student model을 사용한 Knowledge Distillation 논문과 다르다. (추후 Knowledge Distillation 논문을 따로 정리해서 올릴 예정.)
Noising Student
noise는 크게 input noise와 model noise, 2가지 방식으로 줬다. Input noise는 data augmentation을 사용하고 model noise로는 dropout 과 stochastic depth를 사용했다. Teacher model은 pseudo label을 생성하는 동안 model noise를 활용함에 따라 ensemble의 효과를 얻을 수 있고 반면 student는 model noise를 사용하지 않아 single model처럼 작동하게 된다. 즉 이는 student가 더욱 강력한 ensemble model을 흉내내려고 노력할 것이다.
다른 테크닉으로는 data filtering, balancing 등을 사용했다.
3. Experiments
현재는 SOTA가 아닌 만큼 실험 부분은 대략적인 표와 그래프로 대체한다.
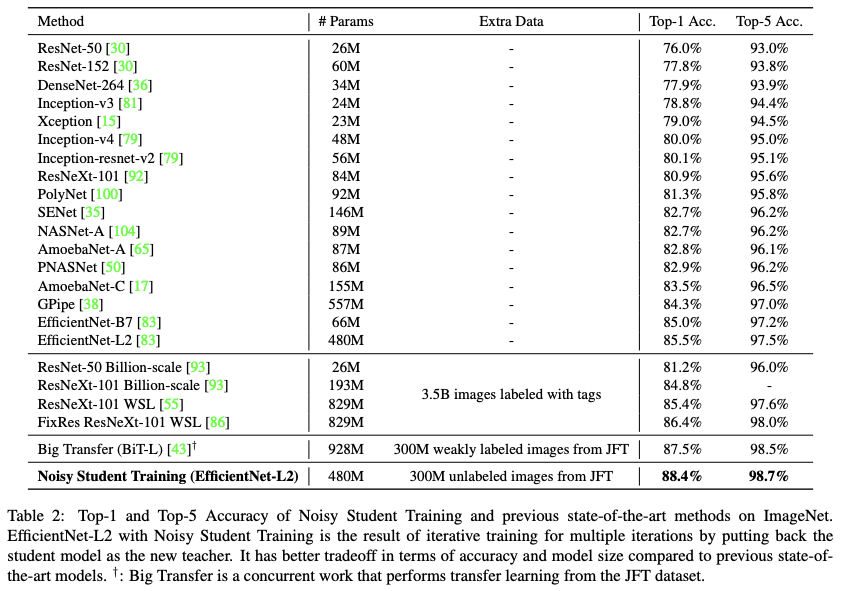
여기서 EfficientNet-L2는 저자들이 새롭게 B7에서 더 deep하고 wide하지만 lower resolution을 사용하도록 scale-up 시킨 버전을 의미한다.
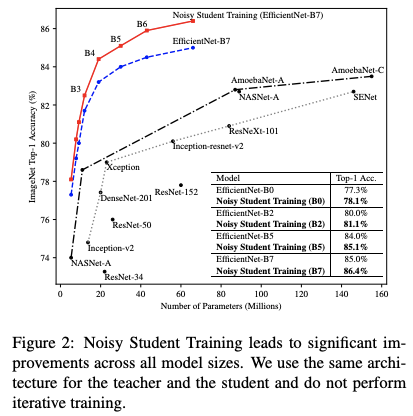
아 그리고 이 방식은 hard label보다 soft label을 사용했을 때 성능이 더 좋다. 사실 처음에 이 논문을 읽을때만 해도 정확하게 이해가 되지않았는데 얼마전 Knowledge Distillation 논문을 보니까 어느정도 이해가 됐다. softmax를 거친 후에 나오는 확률값들에도 정답이 아니지만 어느 정도 중요한 정보를 가지고 있다는 것이다. 말로 설명하기는 조금 까다롭지만 조금만 더 생각해보면 이해가 될 것이다.
다 읽고..
Knowledge Distillation에서 영감을 받은 논문이지만 어느정도 noise를 추가하고 여러번의 iteration을 통해 teacher-sutdent 학습을 반복하는 점이 달랐다. Noise 추가 덕분에 ImageNet-A, -C, -P에서도 나름 robust한 결과를 보이는 것을 보니 적절한 noise를 학습에 추가하는 것은 robustness에도, 그리고 teacher의 지식을 뛰어넘는 student를 얻을 수 있음에도 매우 중요하다고 생각한다.
근데 사실 여러 iteration을 반복하며 학습시키는 행위가 robust에 중요한 역할을 한 것인지 아니면 model에 noise를 추가한 것이 더 중요한 역할인지는 헷갈린다. 물론 둘 다 합해져서 이런 결과를 얻었겠지만 더 명확한 대답을 얻고 싶은 마음이 있다.
Comments