
Self-Supervised Deep Visual Odometry with Online Adaptation
13 Jul 2020 | SSL SLAM&VOShunkai Li, Xin Wang, Yingdian Cao, Fei Xue, Zike Yan, Hongbin Zha
Submitted on 13 May 2020
arXiv:2005.06136
SLAM에 대해 잠시 공부할 일이 생겨 읽어본 논문 2편 중 하나이다. CVPR 2020 에 게재된 논문이다.
최근 Visual Odometry 기술을 사용하여 비디오 영상으로 부터 카메라의 위치와 depth를 추정하는 방식들이 놀라운 성과를 보이고 있다고 한다. 그러나 현존하는 VO network들은 트레이닝 데이터 셋과 다른 새로운 scene들을 마주했을 때 성능이 크게 하락하는 문제가 있었다. 그래서 저자들은 self-supervised 방식으로 VO network가 계속해서 새로운 환경에 적응할 수 있는 방식을 제안한다.
저자들이 제안한 방식에서는 과거로부터의 풍부한 spatial-temporal 정보를 종합하기 위해 convolutional long short-term memory (convLSTM)와 변화하는 환경에 적응시키기 위해 다른 시간에서 feature distribution을 정렬하는 online feature alignment method가 포함된다.
1. Introduction
pre-trained VO network들을 open world에 적용하면 새로운 scene으로의 일반화가 어려워 실제 적용에 있어 심각한 문제를 불러일으킬 수 있다. 그렇다고 타겟 도메인에 대해 pre-trained network를 fine-tuning하는 것은 그 즉시 충분한 데이터를 얻기 어려워 현실에서 적용하기가 어렵다. 그러나 저자들은 real-time에서 변화하는 환경에 대해 자기 자신을 적응하도록 하는 네트워크를 고안해낸다. (we learn as we perform)
이들 논문을 요약하자면 :
- self-supervised 방식으로 unseen environments에 대해 끊임없이 적응하도록 하는 oneline meta-learning algorithm을 제안한다.
- VO network는 더 나은 추정과 현재 프레임에 대해 빠르게 적응하기 위해 convLSTM을 사용하여 과거의 경험을 이용한다.
- open world에서 변화하는 데이터 분포를 다루기 위해 feature alignment 방식을 제안한다.
2. Related works
Learning-based VO는 최근에 많이 연구되고 있는 분야이다. 유명한 네트워크로는 pose와 depth 추정을 동시에 하기 위해 두 개의 네트워크를 쓰는 DeepTAM과 반복해서 pose를 추정하도록 sequential correlation을 이용하기 위해 RNN을 사용하는 DeepVO가 있다. 그러나 이 두 가지 방식은 실제로 사용하기 비싸고 실용적이지 않은 ground truth를 필요로 하는 문제가 있다.
이러한 문제를 피하기 위해서 self-supervisedx VO가 최근 각광받고 있다. 여기에는 photometric loss를 줄임으로써 학습할 pose와 depth의 3D geometric constraint를 이용하는 SfMLearner와 VO를 sequential generative task로 정의하고 scale drift를 줄이기 위해 RNN을 사용하는 SAVO 등이 존재한다. 본 논문에서는 SfMLearner와 SAVO방식의 아이디어를 채택했다고 한다. 사실 이렇게 요약된 글로 본 SfMLearner와 SAVO는 크게 와닿지 않지만 반드시 필요한 내용은 아닌 것 같아 넘어간다.
Meta-learning이란 빠른 domain adaptation을 위해 더 효과적인 learning rule을 학습하도록 데이터 속 내재된 구조를 이용하는 방식이다. 본 논문에서는 모델을 learning rule로 제한하고 새로운 태스크에 네트워크게 빠르게 적응하게 하기 위해 stochastic gradient descent를 사용한 Model Agnostic Meta-Learning (MAML)과 가장 유사한 방식을 사용한다.
3. Problem setup
3.1. Self-supervised VO
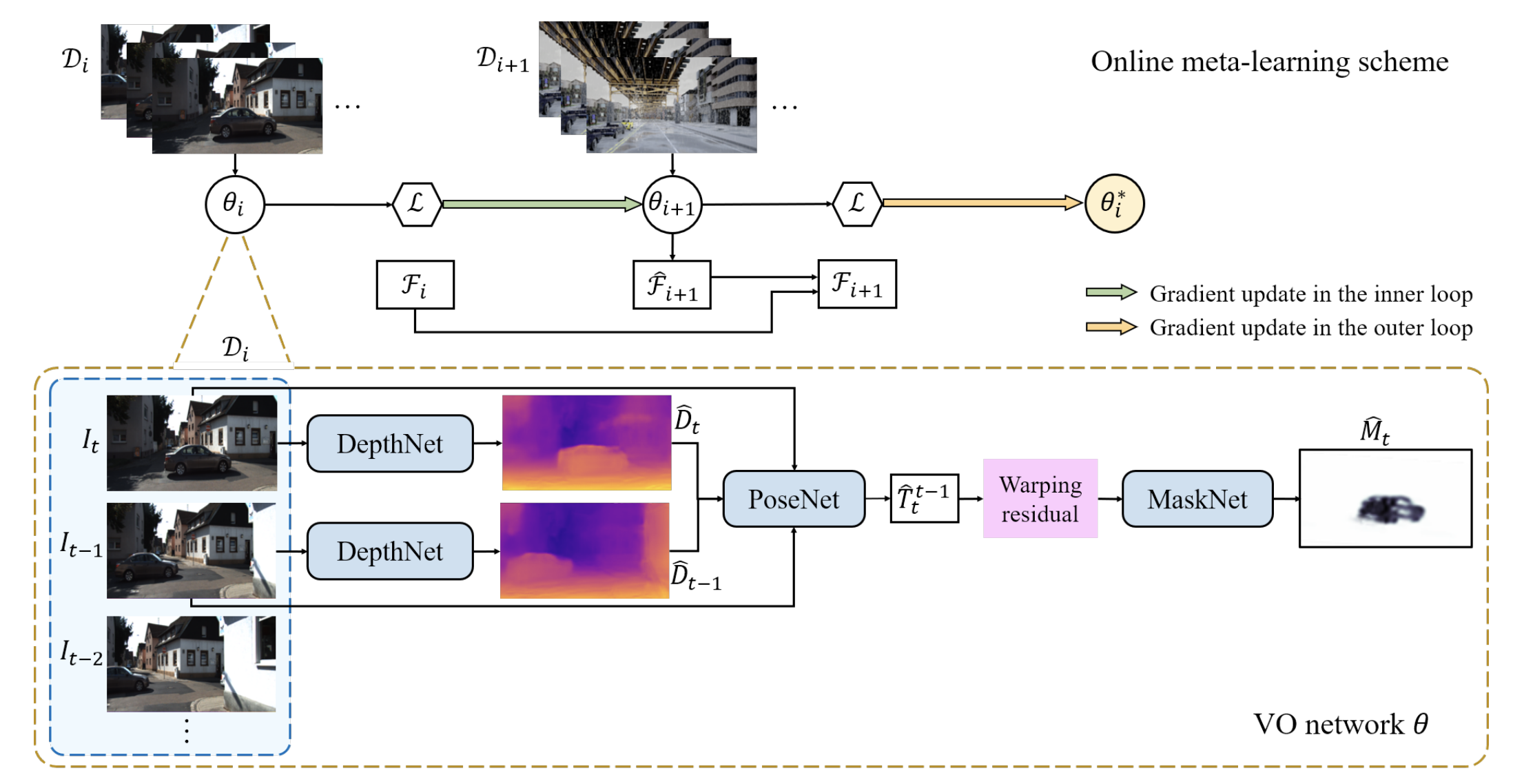
그림에서 DepthNet은 현재 프레임 \({I_t}\)의 depth \(\hat{D_t}\)를 예측한다. PoseNet은 stacked monocular image들인 \(I_{t-1}\), \(I_t\)와 \(\hat{D}_{t-1}\), \(\hat{D}_{t}\)를 사용하여 상대적인 pose \(\hat{T}_t^{t-1}\)를 regress한다. Differentiable image warping으로 \(\hat{I}_t\)를 재구성하기 위해 뷰 합성이 적용된다. (–> 사실 이 부분이 정확하게 이해되지 않아서 코드를 좀 보고 싶은데 코드가 없다…ㅜㅜ)
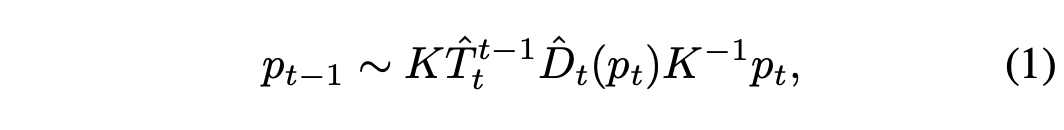
위식에서 p들은 각 이미지들 픽셀의 동차좌표이고 K는 camera intrinsic을 의미한다. 무튼 그래서 MaskNet이 warping residual (우리말로 왜곡잔차라 해야하나..?) \(\lvert \lvert \hat{I}_t - I_t \lvert \lvert\) 를 따라서 per-pixel mask \(\hat{M}_t\)를 예측한다.
3.2. Online adaptation
오픈월드에서는 계속해서 변화하는 scene들을 수집하기 때문에 트레이닝 데이터와 테스트 데이터들이 더이상 비슷한 visual appearance를 공유하고 있지 않고 현재 뷰에서의 데이터들이 이전의 뷰에서의 것들과 다를 수 있다. 단순한 방법으로는 \(\theta_0\)를 \(D^{train}\)으로 pretrain시킨 \(\theta\)로 넣고 아래 식을 계산하는 것이다.
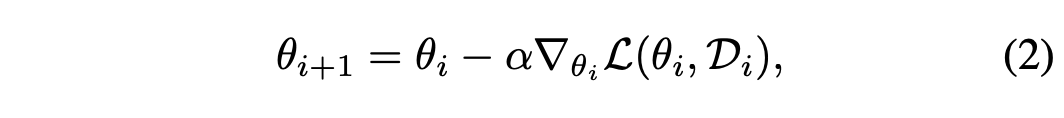
근데 이 방식은 temporal perceptive field of the leraning object \(L(\theta_i, D_i)\)가 1이다. 즉, 오로지 현재 인풋인 \(D_i\)에만 의존하고 이전의 데이터와는 아무런 상관관계가 없다는 말이다. 이렇게 되면 gradient가 각각의 iteration에 대해서 일관성 없이 stochastic해지는 문제가 발생한다.
4. Method
빠른 online adaptation을 위해 다른 시간으로부터의 correlation을 이용하는 방법을 제시한다.
4.1. Self-supervised online meta-learning
저자들은 online learning objective를 \(L(\theta_i, D_i)\)dptj \(L(\theta_{i+1}, D_{i+1})\)까지 확장을 시킨다.
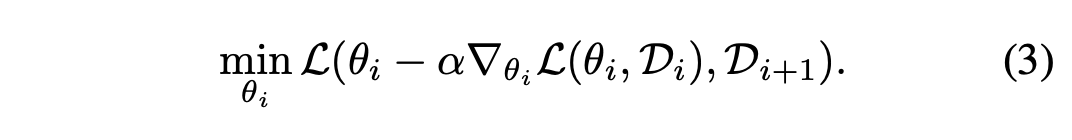
위 식의 왼쪽 부분은 Eq (2).와 동일하며 이는 즉, \(\theta_{i+1}\)를 가리킨다. 이렇게 함으로써 temporal perceptive filed는 2가 된다. 이렇게 하면 현재 iteration i 가 아닌 그 다음 iteration인 i+1에서의 test error를 최소화하도록 학습이 된다. 즉, i time에서 i 뿐만 아니라 그 다음 시간인 i+1에서도 더 잘 작동하도록 하는 \(\theta_i\)를 학습하는 것이다.
4.3. Feature alignment
저자들은 feature alignment에 앞서 source domain에 대해 학습을 시킬 때 Layer Nomalization(LN)로 feature map tensor 속의 feature들에 대한 통계치를 수집했다.
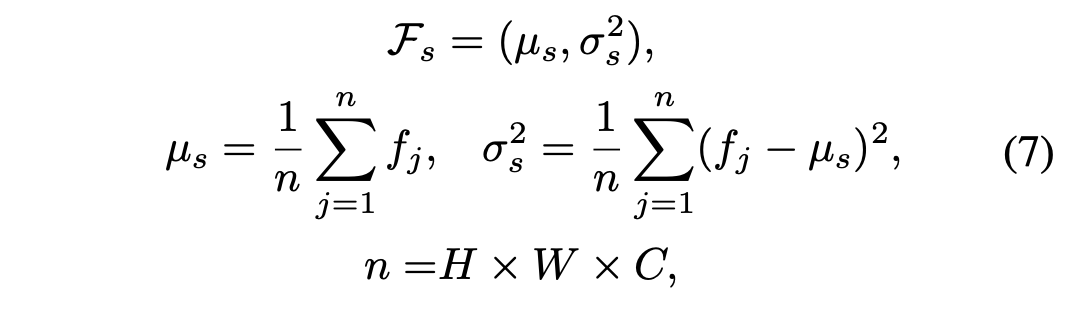
여기서 H, W, C는 각각의 feature map들의 height, width, channel을 의미한다. 그 다음 타겟 도메인에 적용할 떄 i=0에서 feature statistic들로 초기화 시켜준다.
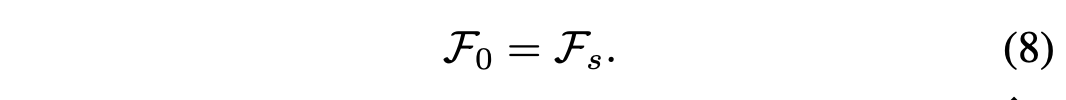
그 다음 각각의 iteration에서 feature 통계치들은 Eq (7).에 의해 계산이 된다. 그리고 나서 이전의 통계치들을 이용하여 feature 분포들은 다음과 같이 정렬된다.
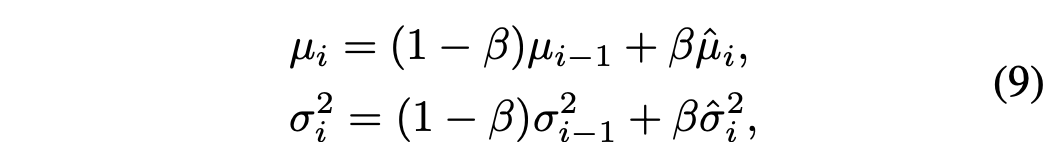
위의 베타는 hyperparameter이며 feature alignment가 끝나고 나면 다시 아래의 식을 사용하여 normalize 시킨다.
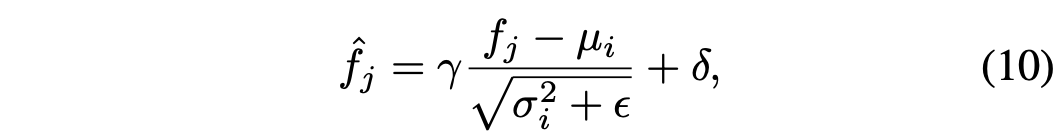
위와 같은 방식을 사용하여 변화하는 환경속에서 정적이지 않은 피처 분포들이 correlation을 갖도록 할 수 있다. 이는 도메인이 서로 비슷할 수록 더 좋은 성능을 보이는데 그건 당연한 것 같다… ㅎ
다 읽고..
실험 부분은 뭐 다른 방식보다 수렴 속도가 빠르고 정확도도 더 높았다고 한다. 따로 정리는 하지 않았지만 그렇다. 처음 읽는 VO 관련 페이퍼라서 조금 읽는데 무슨 말인지 모르겠는 부분이 많지만 그래도 흥미있는 논문인 것 같았다. 첫 페이퍼다 보니 다른 VO 논문과의 비교가 어려워 본 논문이 어느 수준으로 좋은지는 체감하지 못했지만 다음번에도 관련 논문을 시간이 된다면 읽어보고 싶다는 생각이 들었다. 그리고 구현된 방식이 궁금하여 코드를 보고 싶지만 코드는 아직 오픈이 안 된 것 같아 아쉽다.
Comments