
GridMask Data Augmentation
27 Apr 2020 | AugmentationPengguang Chen, Shu Liu, Hengshuang Zhao, Jiaya Jia
Submitted on 13 Jan 2020 (v1), last revised 14 Jan 2020 (this version, v2)
arXiv:2001.04086
지금까지 information dropping를 이용하는 이미지 증대 기법은 많이 등장했다. 하지만 이들은 이러한 dropping에 있어서 중요한 점을 알아내는데 바로 연속적인 지역의 과도한 삭제 또는 보존을 피하는 것이 information dropping 방식의 핵심 포인트라는 것이다. 즉, 이미지 패치의 삭제와 보존이 밸런스를 맞춰야 한다. 이를 뒷받침하기 위한 주장은 다음과 같다.
- 과도한 삭제는 오브젝트의 중요 부분을 제거할 뿐만 아니라 context information도 삭제할 수 있다. 그래서 삭제 후 보존된 부분들이 이미지의 클래스를 정의하기엔 충분한 정보를 가지고 있지 않다는 것이다.
- 과도한 보존은 오브젝트들을 건드리지 않을 수도 있다. 즉, 학습에 영향을 미칠만한 변화가 없다는 것이다.
 Figure 1. Unsuccessful examples by previous strategies
Figure 1. Unsuccessful examples by previous strategies
위의 예를 보면 기존의 정보드랍 기법들(Cutout, HaS)이 과도한 이미지의 삭제 또는 보존이 된 예시이다. 이를 피하기 위해 저자들은 균일하게 분포된 정사각 지역을 삭제하면서 구조화된 제거를 실시한다.
다른 기법들과 간단히 비교를 해보자.

Cutout은 학습 데이터에 무작위로 사각 영역을 제거하는 기법이고 Mixup은 학습 데이터셋에서 무작위로 두가지 샘플들을 뽑아 이미지와 레이블 모두 선형 보간법을 적용하는 기법이다. 두 가지 방식은 오브젝트의 덜 중요한 부분에 집중하지 않게 함으로써 네트워크의 일반화 성능을 높일 수 있다. 그러나 두 방식은 유익한 정보를 가진 픽셀들을 제거하거나 국소적으로 모호하고 부자연스럽다는 단점이 있다. 그러나 두 방식은 유익한 정보를 가진 픽셀들을 제거하거나 국소적으로 모호하고 부자연스럽다는 단점이 있어 이를 극복하기 위해 Cutmix와 Gridmask 기법이 등장했다.
Cutmix는 단순히 사각 영역을 제거하는 Cutout 기법과 달리 제거된 영역을 다른 이미지의 패치로 대체하는 기법이다. 정보를 제공하지 않는 픽셀을 없애고 모호함을 제거함으로써 학습의 효율을 높였다. 한편 Gridmask는 연속적인 영역의 과도한 삭제 또는 보존이 오히려 학습을 방해한다고 주장한다. 이들은 그리드 방식의 제거를 통해 삭제될 영역과 보존될 영역의 균형을 유지하여 효과적으로 학습 성능을 올렸다.
본 논문에서도 사실 Cutmix와 Gridmask의 성능 비교에는 그닥 초점을 두진 않았다. 어느정도 컷믹스의 성능이 괜찮아서 그런가 싶다…
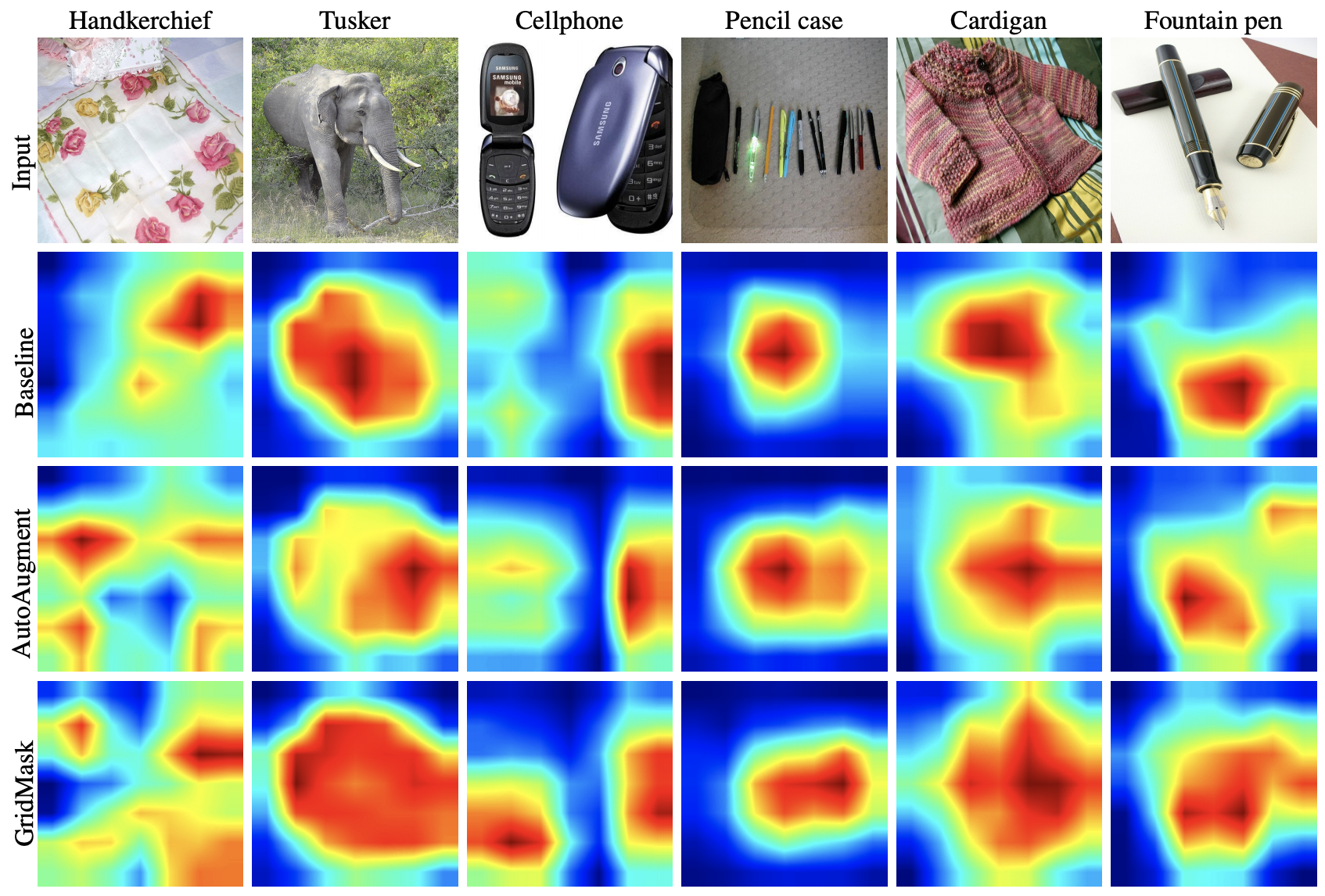 Figure 6. Class activation mapping (CAM) for ResNet50 model
Figure 6. Class activation mapping (CAM) for ResNet50 model
trained on ImageNet, with baseline augment, AutoAugment or our GridMask.
위 그림은 class activation mapping(CAM)을 통해서 각 기법들을 사용했으 ㄹ때 모델이 어느 부분에 집중하며 학습하고 있는지를 보여준다. 여기서 우리가 알 수 있는 것은 더 뛰어난 성능을 보여주는 증대 기법일수록 모델이 더 넓은 지역을 볼 수 있게 한다는 것이다. 또한 AutoAug와 Gridmask를 비교하자면 cellphone 사진에서 AutoAug는 하나의 핸드폰에만 집중하고 있지만 GridMask는 양쪽 핸드폰 모두에 집중을 하고 있다.
AutoAugment. AutoAugment는 논문 발표시기 SOTA augmentation 기법이다. 이 기법은 강화학습을 통해 존재하는 증대 기법 policy들의 조합을 찾아내 만든 증대 기법이다.
다 읽고..
이번 Bengali.AI 캐글 대회에서 사용했던 data augmentation 기법이다. 사실 당시에는 논문을 읽어보지 않고 그냥 바로 코드를 긁어서 가져다 썼는데 이번에 논문 작성하면서 읽을 시간이 생겨 읽어보았다. 핵심 아이디어는 가릴 부분, 남길 부분의 밸런스를 잘 맞추는게 중요하다는 것이다. 이들은 논문의 끝에서 Mixup과 GridMix를 결합했을 때 모든 regularization 방법들 중 최고 점수를 얻을 수 있었다고 하지만 사실 Cutmix 와 상세한 비교가 이루어지지 않았다는 점이 아쉽다.
Comments