
Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
20 Mar 2020 | SSL Contrastive--Learning FacebookKaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick (Facebook AI Research (FAIR))
(Submitted on 13 Nov 2019 (v1), last revised 14 Nov 2019 (this version, v2))
arXiv:1911.05722
MoCo(Momentum Contrast)를 이용한 Facebook 팀의 논문이다.
1. Introduction
Unsupervised representation learning은 NLP(natural language processing, 자연어처리)에서 굉장히 성공적이지만 컴퓨터 비전에서는 여전히 supervised 방식이 더 우세를 차지하고 있다. 아마 그 이유는 그들 각각의 signal space에서의 차이에서 나오는 것이라 말한다. 언어처리에서는 토큰화된 사전을 위한 discrete signal spaces (words, sub-word units..)이 있기 때문에 unsupervised가 좋은 성능을 보일 수 있지만 컴퓨터 비전은 raw signal이 연속적이고 고차원의 공간에 존재하여 단어와 같이 인간의 소통을 위해 구조화되지 않았기 때문에 사전 구축과 더 관련이 있다.
이전의 논문들은 contrastive loss와 관련된 방식으로 unsupervised visual representation learning을 보여줬다. 이러한 방식들은 dynamic dictionaries를 구축하는 것으로 간주될 수 있다. 사전의 “keys” (tokens)들은 data (images or patches)로부터 샘플링될 수 있고 encoder network에 의해 표현될 수 있다. Unsupervised learning은 인코더를 dictionary look-up을 수행하도록 학습시킨다. 인코딩된 query는 matching key와 비슷해야만 하고 다른 것들과는 또 달라야만 한다. 학습은 contrastive loss를 줄이는 방향으로 진행된다.
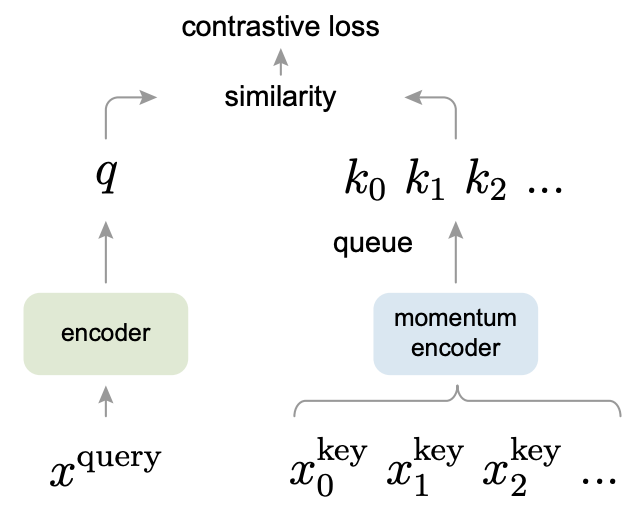 Figure 1. Momentum Contrast (MoCo) trains a visual representation encoder
Figure 1. Momentum Contrast (MoCo) trains a visual representation encoder
by matching an encoded query q to a dictionary of encoded keys using a contrastive loss.
이들은 contrastive loss를 사용하는 unsupervised learning을 위해 크고 일관적인 사전을 구축하는 방식으로 Momentum Contrast (MoCo)를 선보였다. Figure 1.에서 대략적으로 볼 수 있고 자세한 내용은 뒤에서 다룬다.
2. Related Work
Loss functions
Loss function을 정의하는 방식에는 여러가지가 있다.
Loss function을 정의하는 흔항 방식 중 하나는 model로 부터 나온 prediction값과 fixed target 값 사이의 차이를 측정하는 것이다. 이 방법에는 L1 또는 L2 losses를 이용해서 input pixel을 재건축하는 방식 (e.g., auto-encoders) 또는 cross-entropy나 margin-based loss를 사용하여 input을 사전 정의된 카테고리로 분류하는 방식이 있다.
Contrastive losses는 representation space에서 sample pair들의 유사성을 측정한다. 고정된 타켓과 인풋을 매칭하는 대신에, contrastive loss formulations에서는 타겟이 학습 동안에도 그때그때마다 다양할 수 있고 네트워크로부터 계산된 data representation의 관점에서 정의될 수도 있다.
Adversarial losses는 확률분포(probability distributions) 사이의 차이를 측정한다. 이 방식은 unsupervised data generation에서 널리 성공적으로 쓰이는 기술이다. GAN(generative adversarial networks)과 NCE(noise-contrastive estimation)과 관련이 있다.
3. Method
3.1. Contrastive Learning as Dictionary Look-up
Contrastive learning과 그것의 최근 발전은 dictionary look-up task를 위한 인코더를 학습시키는 것으로 생각될 수 있다. 인코딩된 query \(q\)와 사전의 key인 인코딩된 샘플들 \(\{k_0, k_1, k_2, ...\}\)이 있다고 생각하자. 사전 안에 \(q\)랑 매치되는 하나의 키 (\(k_+\))가 있다고 가정하면 contrastive loss는 \(q\)가 그것의 positive key인 \(k_+\)와 비슷하고 다른 키들(negative keys for \(q\))과는 비슷하지 않을 때 loss 값이 작아지는 function이다. 유사성은 dot product로 계산이되고 InfoNCE라고 불리는 contrastive loss function의 형태가 이 논문에서 사용된다 :
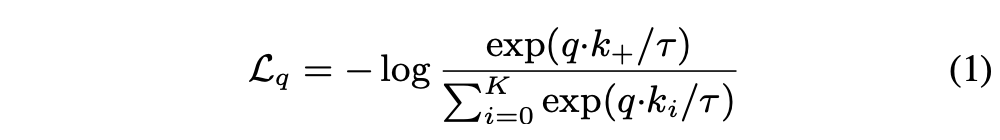
여기서 \(𝜏\)는 temperature hyper-parameter이다. 분모의 합은 하나의 positive와 K개의 negative 샘플들의 합을 의미한다. 직관적으로 이 loss는 \(q\)를 \(k_+\)로 분류하려고 노력하는 (K+1)-way softmax-based classifier의 log loss임을 알 수 있다. Contrastive loss function은 margin-based losses나 NCE losses와 같은 다른 형태로도 표현이 가능하다.
Query representation은 \(q = f_q(x^q)\)이다. 여기서 \(f_q\)는 인코더 네트워크이고 \(x^q\)는 쿼리 샘플이다. 여기서 input \(x^q\)은 이미지, 패치, 일련의 패치들을 구성하는 context가 될 수 있고 네트워크 \(f_q\)도 identical, parially shared 또는 더 복잡할 수도 있다.
3.2 Momentum Contrast
Contrastive learning은 이미지와 같은 고차원의 연속적인 input에 대해 discrete한 사전을 구축하는 방법이다. 이 사전은 키들이 랜덤하게 샘플링되고 키 인코더가 학습동안에 진화한다는 점에서 dynamic하다. 이들은 사전 키들을 위한 인코더가 그것의 진화에도 불구하고 가능한한 일관적인 동안에 좋은 feature들이 풍부한 negative 샘플들을 가지는 큰 사전에서 학습될 수 있다고 가설을 세웠다.
Dictionary as a queue. 이들의 핵심 접근법은 사전을 데이터 샘플들의 queue로 유지시키는 것이다. 이렇게 하면 바로 앞의 미니 배치에서 인코딩된 키를 재사용할 수 있다. 큐를 도입하면 사전의 크기가 미니 배치 사이즈에서 분리가 된다. 그래서 이들의 사전 크기는 전형적인 미니 배치 크기보다 훨씬 더 클 수 있고 하이퍼파라미터를 통해 유연하고 독립적으로 설정될 수도 있다.
사전 속 샘플들은 점진적으로 바뀐다. 현재 미니배치가 사전에 enqueue되며 큐에서 가장 오래된 미니 배치가 제거된다. 사전은 항상 모든 데이터의 샘플된 서브셋을 표현하고 있으며 이 사전을 유지하는데 드는 extra computation은 관리할 수 있을 정도이다. (메모리 효율도 괜찮은 수준이라는 뜻) 또한 큐 안의 가장 오래된 미니 배치를 제거하는 건 도움이 된다. 왜냐하면 이 인코딩된 키들은 가장 오래되어 최신키와 일치하지 않기 때문이다.
Momentum update. 큐 사용은 사전을 크게 만들 수 있지만 이는 곧 back-propagation를 통해 키 인코더를 업데이트하는 것이 어려워진다 (gradient는 큐 안의 모든 샘플들에 전파되어야 함). Näive solution은 이 gradient를 무시하고 쿼리 인코더 \(f_q\)에서 키 인코더 \(f_k\)로 복사 하는 것이다. 그러나 이 방법은 실험에서 안 좋은 결과를 보였다. 이들은 이 실패가 key representation의 일관성을 줄이는 급격한 인코더 변화에서 왔다고 가설을 세웠다. 이 문제를 다루기 위해 momentum update를 제안했다.
\(f_k\)의 파라미터를 \(θ_k\), \(f_q\)의 파라미터를 \(θ_q\)를 표현한다. 그 다음 \(θ_k\)를 다음 방식으로 업데이트한다 :
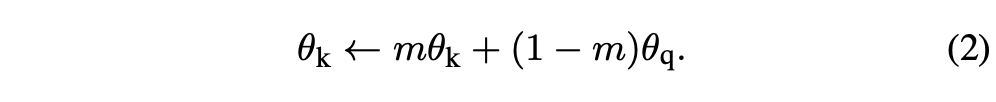
여기서 \(m ∈ [0,1)\)은 momentum coefficient이다. Back-propagation을 통해 오직 파라미터 \(θ_q\)만 업데이트 된다. Eqn.(2)의 모멘텀 업데이트는 \(θ_k\)가 \(θ_q\)보다 더욱 스무스하게 진화하도록 만든다. 그 결과로 큐 안의 키들이 다른 인코더에 의해 인코딩 되더라도 (다른 미니배치니까) 인코더들 간의 차이를 작게 만들 수 있다. 상대적으로 큰 모멘텀 (\(e.g.\), \(m\) = 0.999)이 작은 것 보다 (\(e.g.\), \(m\) = 0.9) 효과가 훨씬 좋았다. 이는 곧 천천히 진화하는 키 인코더가 큐를 활용하는 데 있어 핵심 포인트라는 걸 의미한다.
Relations to previous mechanisms. MoCo는 contrastive loss를 사용하는 general mechanism이다. 이들은 Figure 2.에 보이는 2가지 다른 general mechanism들과 비교를 한다. 이들은 사전 크기와 일관성에서의 property가 다 다르다.
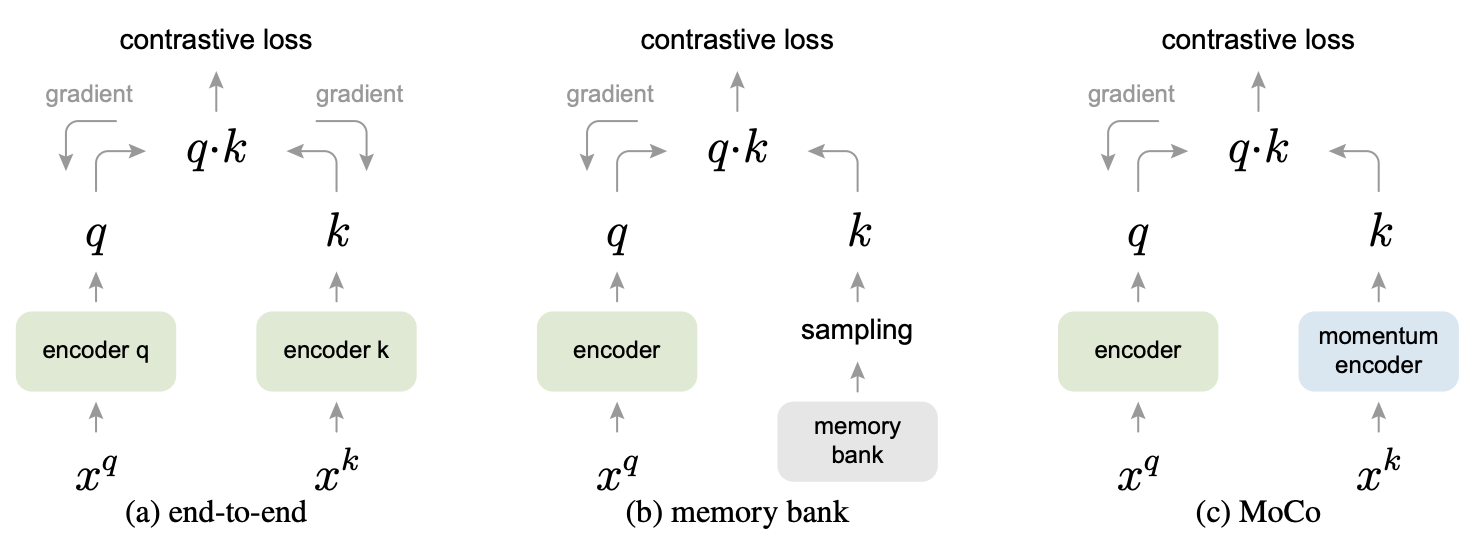 Figure 2. Conceptual comparison of three contrastive loss mechanisms
Figure 2. Conceptual comparison of three contrastive loss mechanisms
Back-propagation에 의한 end-to-end 업데이트는 natural mechanism이다 (Figure 2a.). 현재 미니배치의 샘플들을 사전으로 쓰고 이로 인해서 같은 세트의 인코더 파라미터에 의해 키들이 일관적으로 인코딩된다. 그러나 사전 크기는 GPU 메모리 사이즈에 제한받아서 미니배치 사이즈에 결합된다. 또한 큰 미니배치 optimization은 힘든 일이다.
다른 mechanism은 memory bank 방식이다 (Figure 2b.). 메모리 뱅크는 데이터셋의 모든 샘플들의 representation들로 구성된다. 각각의 미니배치를 위한 사전들은 back-propagation 없이 메모리 뱅크로부터 랜덤하게 샘플링된다. Back-propagation이 필요하지 않으므로 큰 사전 사이즈를 지원하지만 메모리 뱅크 속 샘플의 representation은 마지막으로 나타났을 때만 업데이트가 되었다. 따라서 샘플링된 키는 기본적으로 과거 에포크에 걸쳐 여러 다른 단계의 인코더에 대한 것이므로 일관성이 떨어진다. 이것의 모멘텀 업데이트는 인코더가 아니라, 같은 샘플의 representation에 적용이 된다. 이 모멘텀 업데이트는 MoCo와는 관계가 없다. MoCo는 모든 샘플의 track을 유지하지 않기 때문이다. 더욱이, MoCo는 메모리 효율이 더욱 좋고 memory bank에서는 불가능한 billion-scale 데이터에 대해서도 학습이 된다.
3.3. Pretext Task
여기서는 contrastive learning에 집중하기 위해 pretext task는 주로 instance discrimination task를 사용했다. Query와 key가 같은 이미지로부터 생성됐으면 positive pair로 간주하고 아니면 negative로 생각한다. Positive pair를 생성하기 위해서 랜덤 augmentation을 사용한 같은 이미지에서 2개의 random “views”를 선택한다(서로 다른 2가지 버전의 random augmentation을 같은 이미지에 적용함). 쿼리와 키는 각각의 인코더인 \(f_q, f_k\)에 의해 인코딩되며 인코더는 아무 CNN이 될 수 있다.

Algorithm 1에 해당 pretext task에 대한 슈도코드가 적혀있다. 현재 미니배치에 대해서 이들은 positive sample pairs를 만들기 위해 쿼리와 그에 해당하는 키들을 인코딩하고 negative 샘플들은 큐로부터 생성해낸다.
Shuffling BN. 인코더 \(f_q, f_k\)는 모두 Batch Normalization (BN)을 가지고 있다. 하지만 이 BN이 오히려 좋은 representation을 학습하는 것에 방해가 되는 것을 발견했다. 이는 모델이 pretext task를 속여 쉽게 low-loss solution을 찾는 것 같았다. 아마 (BN에 의해서 발생한) 샘플들 간 배치 내 통신이 정보를 누출하기 때문일 수 있다.
저자들은 이 문제를 shuffling BN을 사용하여 문제를 해결했다. 다수의 GPU를 사용하고 각각의 GPU에서 독립적으로 샘플들에 BN을 적용했다. 키 인코더 \(f_k\)에 대해서는 GPU에 분포시키기 전 현재 미니 배치 내 샘플 순서를 랜덤 셔플했고 인코딩 후 다시 또 셔플했다. 이렇게 하면 쿼리와 positive 키를 계산하는데 사용되는 배치 통계가 서로 다른 두 개의 서브셋으로부터 제공되도록 한다. 이 방식으로 cheating issue를 없앴고 BN으로부터 좋은 효과를 얻을 수 있도록 했다.
Shuffled BN을 MoCo와 end-to-end에 사용했고 메모리뱅크는 positive key들이 과거의 다른 미니 배치로부터 오기 때문에 이런 이슈가 존재하지 않아 적용을 할 필요가 없다.
4. Experiments
ImageNet-1M (IN-1M) 1000개의 클래스를 가진 1.28 million 이미지의 트레이닝 셋을 ImageNet-1K라고 부른다. Unsupervised learning에서는 클래스 정보를 사용하지 않기 때문에 이미지 개수를 센다. 이 데이터셋은 클래스간 분포가 골고루 되어 있다.
Instagram-1B (IG-1B) 이 데이터셋은 대략 1 billion개의 인스타그램 이미지를 가지고 있다. 이미지들은 이미지넷 카테고리와 연관있는 1500개의 해시태그로부터 뽑아냈다. 이미지넷 데이터에 비해 상대적으로 정렬이 되어 있지않으며 long-tailed, unbalanced의 분포를 가지고 있다.
Training. 이들은 SGD를 optimizer로 사용한다. Weight decay는 0.0001이고 SGD momentum은 0.9이다. IN-1M에서는 8개의 gpu에 256 사이즈의 미니 배치를 사용했고 초기 lr은 0.03이다. IG-1B에는 64개의 gpu에 1024 사이즈의 미니 배치를 사용했다. 더 자세한 사항은 논문에서 확인할 수 있다.
실험 부분은 표가 많고 직접 읽는 것이 도움이 될 것 같아 ImageNet linear classification 결과표만 올린다.
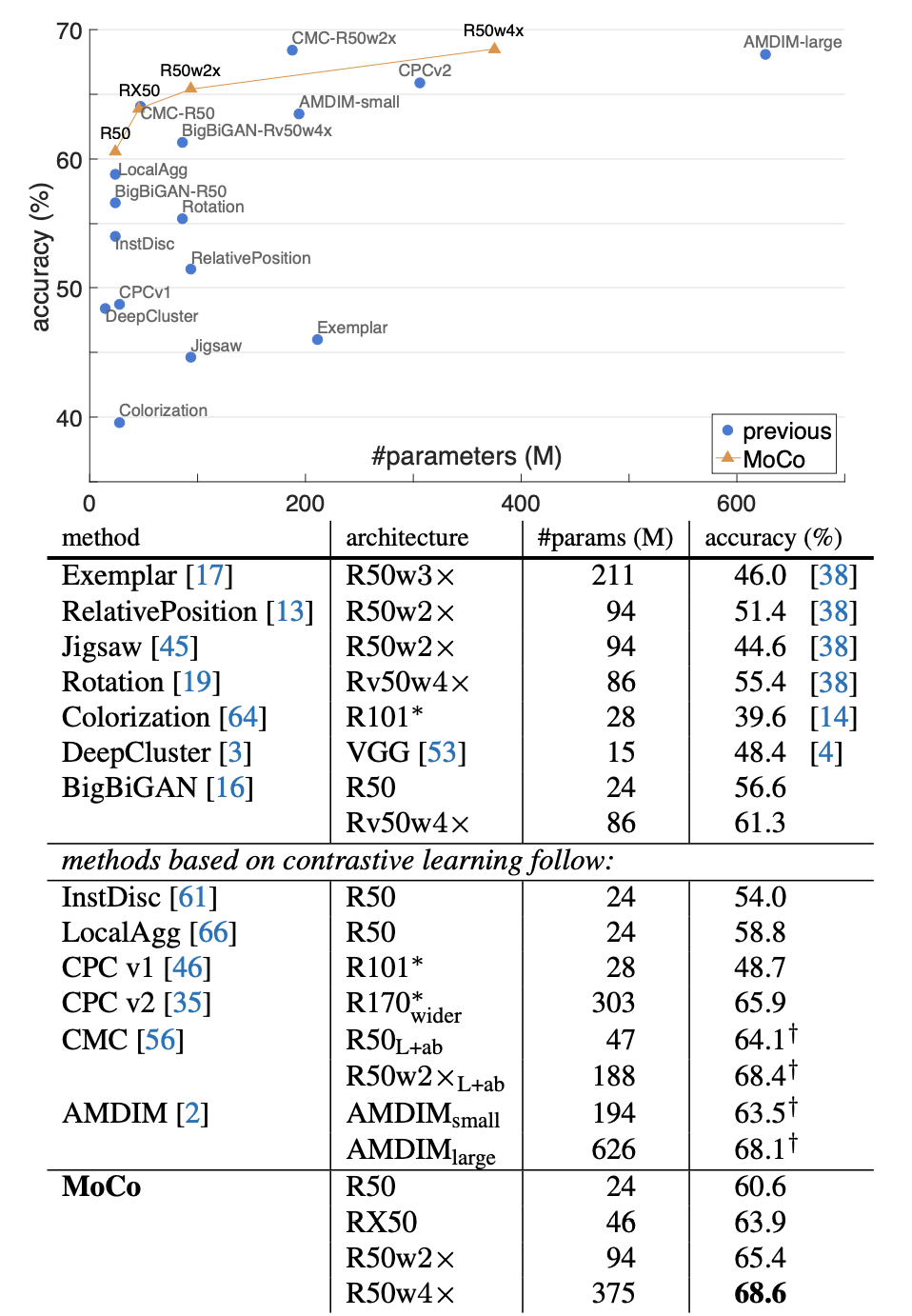
표에서 비교하고 있는 다른 SSL 기법들보다 성능이 높은 것을 볼 수 있다.
다 읽고..
Memory bank를 사용하지 않고 큰 사전을 구축하여 아주 많은 negative들과 비교를 하며 학습을 하도록 한 것이 큰 장점이라고 생각한다. 또한 제목에서 볼 수 있듯이 모멘텀의 효과를 주어 param들을 카피한 부분이 인상적이었다.
Comments