
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
08 Jan 2020 | Architecture Google
Mingxing Tan, Quoc V. Le
(Submitted on 28 May 2019 (v1), last revised 23 Nov 2019 (this version, v3))
arXiv:1905.11946
엄청 핫하게 쓰이고 있는 EfficientNet 에 대한 논문이다. EfficientNet은 크기에 따라 b0, b1 … , b7 까지 있다. 간단하게 요약하자면 width, depth, image resolution 3가지를 하나의 계수로 scale 하여 네트워크의 정확도와 효율성을 높였다.. 라고 적혀있다.

Accuracy를 향상시키기 위해서 대부분 depth, width, image resolution이라는 3개의 dimension을 scale하는데 저자들은 여기서 fixed scaling coefficients를 이용하여 유니폼하게 조정하겠다고 한다.

기존의 네트워크들은 대부분 여러 개의 스테이지로 나눠지고 각 스테이지 안에서도 동일한 layer들이 여러 개 존재하는 형태이다. 따라서 이러한 네트워크를 위와 같은 식으로 정의를 내렸다.

기존 방식에서 depth만 늘려보았다. Depth를 키울수록 성능은 점점 좋아지다가 어느 정도가 지나서 네트워크가 너무 deep해지자 성능향상이 감소했다.

Width도 마찬가지다. 커질수록 점점 성능이 좋아지는가 싶더니 어느 순간 정확도가 빠르게 saturate되는 문제가 있었다.

별 다를 거 없이, resolution에 대해서도 동일한 모습을 보였다. 그래서 그들은 이를 통해 정리를 했다.
[Observation 1]
네트워크의 width, depth, resolution 중 어느 차원을 scale up 시켜도 성능은 향상된다. 그러나 어느 정도 너무 큰 모델에 있어서는 그 성능 향상이 감소한다.

이번에는 \(d\)와 \(r\)을 고정해놓고 width를 늘리는 것은 이전의 실험과 비슷하나 이 때 \(d\)와 \(r\)값을 각각 다르게 해놓고 실험을 했다. 이 때, \(d=1.0\), \(r=1.0\)일 때보다 \(d=2.0\), \(r=1.3\)일 때 같은 FLOPS cost 하에서 더 좋은 성능을 내는 것을 확인할 수 있었다.

Observation 2
성능과 효율성을 높이기 위해서 ConvNet scaling을 진행할 때, width, depth, resolution의 모든 차원의 밸런스를 맞추는게 중요하다. 사실 이전까지도 임의로 이 세 가지의 밸런스를 맞추는 논문이 존재하기는 했으나 이는 수동으로 해야하는 지루한 tuning이었다.
이를 대신하여 저자들은 compound coefficient 를 사용하는 compound scaling method 를 제시한다.

위 피피티 화면을 읽어보면 대충 알파 ɑ, 베타 β, 감마 γ에 따라서 FLOPS가 어느 정도로 증가하는지를 식으로 표현해놓은 것을 알 수 있다.

Baseline network인 F는 고정시키므로 baseline network 의 성능이 중요한 키 포인트이다. 이를 위해 그들은 moblie-size baseline인 EfficientNet을 AutoML을 통해 제작하게 된다. 이 때 사용한 AutoML 방식은 multi-objective neural architecture search를 사용했고 accuracy와 FLOPS 모두를 optimize하는 네트워크를 찾도록 했다.
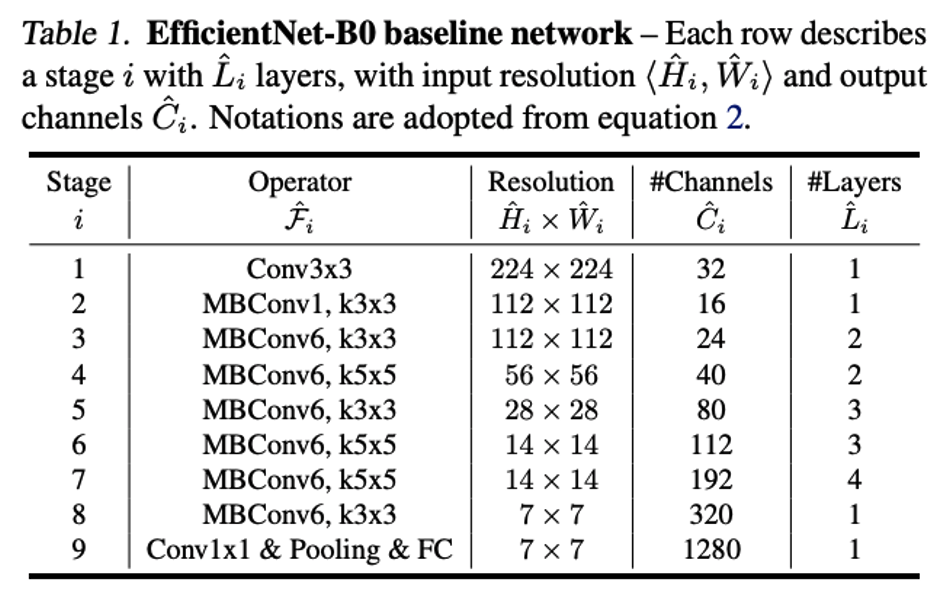
EfficientNet의 baseline인 b0는 위와 같은 구조를 하고 있다.

또한 어떤 방법으로 constant를 찾게 됐는지도 말해주고 있다. 여기서 알파, 베타, 감마는 파이를 1로 고정시켜놓고 small grid search를 통해 찾았고 이때 찾은 알파, 베타, 감마를 사용하여 파이 값을 바꾸며 b0~b7까지 찾았다고 한다.

자신들의 compound scaling method 가 성능향상에 아주 좋다는 것을 보여주기 위해서 이미 존재하는 네트워크인 MoblieNets 과 ResNet에 적용하여 실험을 했다. 이 때 결과는 compound scale을 한 네트워크의 성능이 향상됐음을 볼 수 있다.

본인들이 만든 EfficientNet은 현재 SOTA이던 GPipe의 성능보다 좋았으며 parameter 수는 8.4배나 적다.

또한 B3의 경우 ResNeXt-101보다 parameter 수가 적음에도 비슷하거나 오히려 조금 더 나은 성능을 보였고 FLOPS에서도 큰 차이를 보였다.

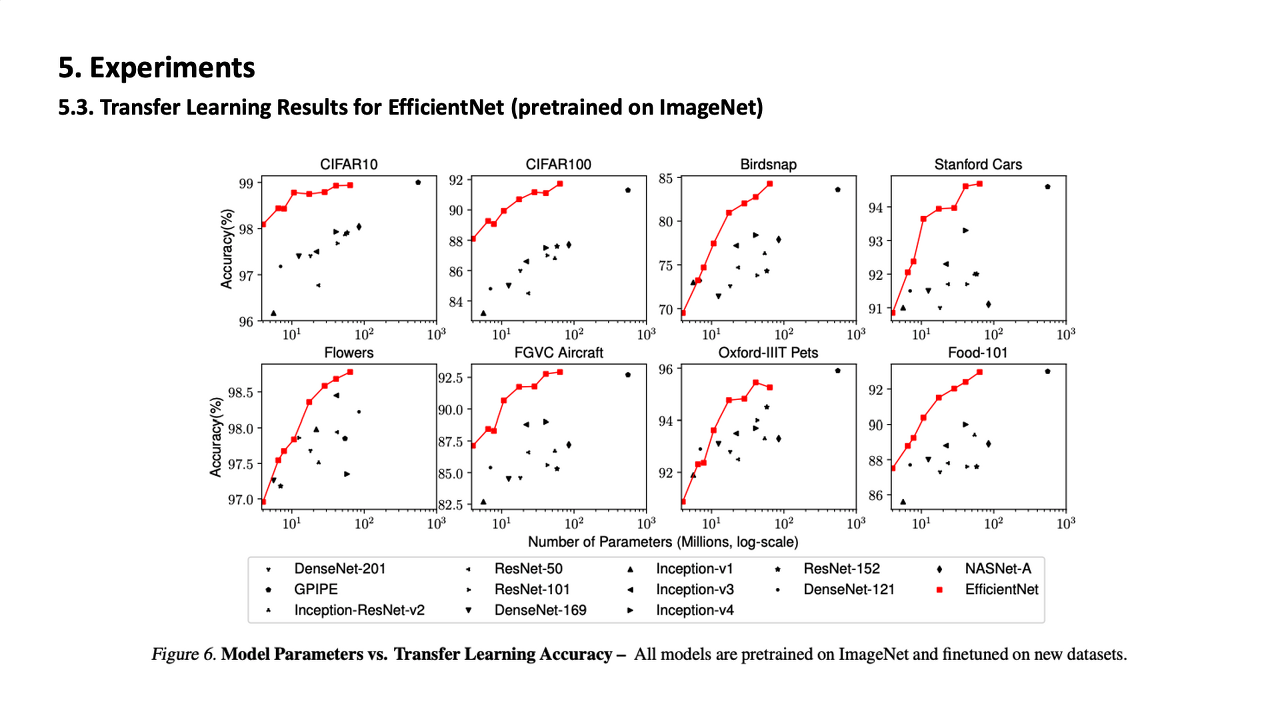
Transfer learning에서도 뛰어난 성능을 보였다고 한다.

마지막으로 그들의 compound scaling이 어떤 효과를 내는지 시각적으로 보여주기 위해서 class activation map도 나타냈다. 아래 사진을 통해서 compound scaling을 한 모델이 훨씬 더 관련있는 object 부분에 집중하고 있는 것을 볼 수 있다.
다 읽고..
이번에 처음 캐글 챌린지에 도전을 해봤는데 캐글 discussion에서 상위권 사람들이 EfficientNet을 사용한다는 것을 알게되었다. 메모리도 적게들고 성능도 뛰어난데 안쓸 이유가 없는 것 같다. 다음에 읽을 architecture 관련 논문을 읽을 때에는 역시 캐글에서 추천받은 GhostNet을 읽을까 싶다.
Comments