
Boosting Self-Supervised Learning via Knowledge Transfer
24 Dec 2019 | SSL Transfer--LearningMehdi Noroozi, Ananth Vinjimoor, Paolo Favaro, Hamed Pirsiavash
(Submitted on 1 May 2018)
arXiv:1805.00385
여태 알던 transfer learning은 pretext task와 target task에 사용할 모델이 동일할 때 가능했었다. 하지만 이 논문에서는 pretext task를 학습한 모델과 target task 를 학습한 모델이 서로 달라도 transfer를 이용한 learning을 가능케 한다. 또한 Jigsaw++ 란 pretext task를 제안했다.
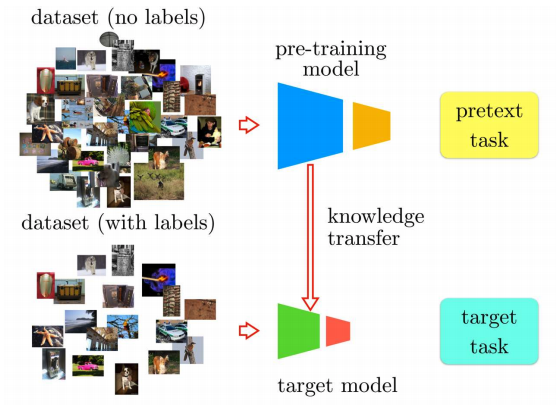
현재까지 많은 SSL은 transfer learning을 이용하지만 이 같은 방법에서의 최대 한계점은 모델 디자인의 선택이었다. 즉, pretext task에서 선택했던 모델과 target task 를 학습할 때 사용할 모델이 동일해야 했다는 점이다. 저자는 이를 극복하여 더 deep한 모델에서도 knowledge transfer를 하는 방법을 작성했다.
우선 그들은 좋은 visual representation space에서 의미적으로 유사한 데이터들은 서로 가까이에 위치할 것이라는 직감을 이용했다.
(a) Self-Supervised Learning Pre-Training

다양한 pretext task를 통해 네트워크를 학습시킨다.
(b) Clustering
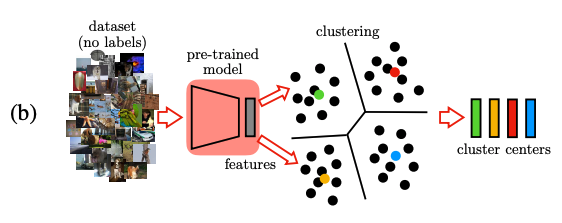
방금 학습시킨 network로 데이터 셋 안의 모든 unlabeled image들에 대해서 feature vectors를 계산한다. (이 때 feature들은 CNN의 중간 layer에서도 추출이 가능하다.) 그리고 나서, feature들을 cluster하기 위해 Euclidean distance를 가지고 \(k\)-means algorithm을 이용한다.
더 자세한 k-means clustering 에 대해서는 아래 블로그를 참고하면 될 것이다. https://ratsgo.github.io/machine%20learning/2017/04/19/KC/
(c) Extracting Pseudo-Labels
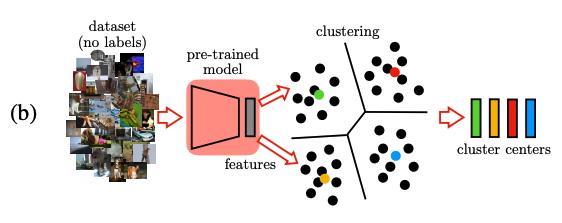
(b) 단계에서 계산해뒀던 각 cluster의 center들은 virtual category로 고려될 수 있다. 각각의 feature vector들의 pseudo-label을 결정하기 위해서 이 벡터들을 가장 가까운 cluster center에 할당했다. 이 때 사용되는 데이터 셋들은 (a) 또는 (b)에서 사용된 것들과 달라도 된다.
(d) Cluster Classification

Target task에 사용될 architecture를 이용하여 간단한 classifier를 학습시킨다. (c)에서 사용되었던 pseudo label을 뽑을 때 썼던 데이터들을 다시 input으로 넣으면서 이번에는 이전에 할당된 pseudo-label을 예측하는 방식의 학습을 진행한다.
결국, classifier는 target architecture 속에서 새로운 representation을 배운다.
해당 논문에서는 jigsaw++ 라는 기존 jigsaw problem의 변형 버전을 사용한다.

- Main image인 (a)와 random image인 (b)가 필요하다.
- 처음에는 (a)를 직소퍼즐과 비슷하게 섞어준다. ==> (c)의 상태가 됨.
- 그리고 나서 random image로부터 random patches 를 교환한다. ==> (d)의 상태가 됨.
(d)가 Jigsaw++ 에서 풀어야 할 퍼즐이다. 이는 기존 Jigsaw 문제보다 훨씬 복잡해진 버전이다.
- 모델은 occluding tile을 찾아야 한다.
- occluding tile 이외의 나머지 타일들로 jigsaw 를 풀어야 한다.
실험 결과
What is the impact of the number of clusters?

\(k\)-means clustering에서는 유저가 직접 cluster의 수를 정해줘야한다. Cluster 수에 따른 영향을 보기 위해 5,00에서 10,000까지 바꿔가며 실험을 진행했다.
그에 따른 결과로는 클러스터의 수에 네트워크가 그렇게 민감하지는 않았다. 어느정도 클러스터의 수가 증가됨에 따라 mAP도 올랐다고 보이지만 이는 클러스터의 수가 커지면 클러스터 당 data의 개수가 줄어드는 효과 때문에 overfit의 원인이 되었기 때문이라고 주장했다..
Transfer Learning Evaluation
PASCAL VOC fine-tuning

결과는 AlexNet 보다 deep한 vgg를 이용했고 Jigsaw++를 pretext task로 사용했고 Cluster classfication을 사용했을 때 가장 성능이 좋았다. 또한 Supervised와 성능차이도 크게 나지 않았음을 보인다.
그들의 knowledge transfer 방식이 더 큰 스케일의 데이터셋과 더욱 deep한 모델을 pre-training에서 사용할 수 있게 했다고 주장한다. (심지어 fine-tuning에서는 AlexNet을 사용)
Linear Classification

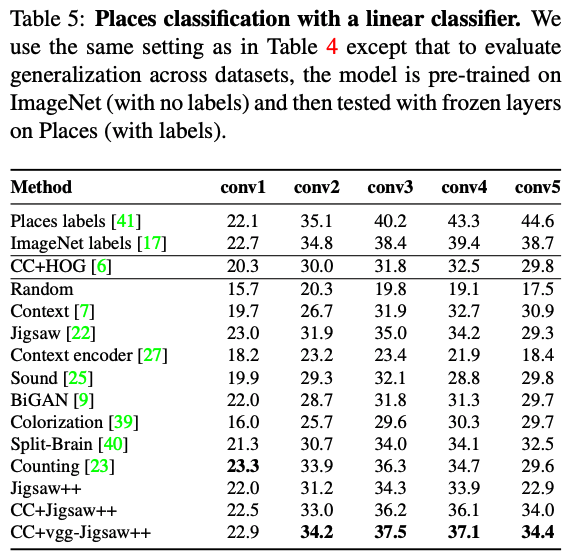
여기서도 vgg를 pre-training에 사용하고 CC와 Jigsaw++를 이용한 모델이 가장 성능이 좋음을 볼 수 있다.
Nonlinear Classification

이 실험은 AlexNet의 마지막 layer에서 nonlinear classifier를 이용했다는 것이다. 이 실험은 CC를 통해 얻은 pseudo-label과 ground truth label 사이의 alignment를 설명할 또다른 방식이라고 한다. 여전히 CC + vgg-Jigsaw++ 가 가장 성능이 좋았다.
Visualization

Alexnet에서 학습된 filter들을 시각화한 버전이다. 여기서 흥미로운 점은 Color dropping인 (c)에서는 color를 볼 수 없다는 것이다. 이러한 사실은 pre-training stage에서 어떠한 색 이미지도 볼 수 없는 color dropping의 방식과 일치했다.

또한 CC+vgg-Jigsaw++에서 학습에서 사용된 sample cluster들을 보여준다.
각 줄은 하나의 cluster center와 가장 가까운 이미지들을 보여준다.
다 읽고..
그들의 knowledge transfer는 꽤나 효과를 보인다고 생각한다. 일단 이전까지의 transfer learning과 다르게 새로운 모델에 적용이 가능하다는 것이 흥미로웠고 그 실험 결과까지 성능이 좋게 나오니 좋은 방법이라 생각한다. :)
Comments