
A Critical Analysis of Self-Supervision, or What We Can Learn from a Single Image
20 Dec 2019 | SSL Augmentation
Yuki M. Asano, Christian Rupprecht, Andrea Vedaldi
(Submitted on 30 Apr 2019 (v1), last revised 26 Nov 2019 (this version, v2))
arXiv:1904.13132
‘Self-supervised task를 통한 학습은 low layer에만 좋은 영향을 준다.’
즉, high-level representation을 배우지 못한다고 주장한다.
그리고 단 한 장의 이미지를 augmentation을 통해 여러 장을 만들고 사용하면 평소의 많은 이미지 학습과 성능이 비슷하다고 주장.

그들은 현재까지 나온 self-supervision 에 대해서 의문을 가졌고 과연 이 self-supervision이 neural net의 각각 다른 파트를 학습하는 데 있어 아주 많은 이미지들에 담겨있는 정보를 모두 이용할 수 있을 것인지를 실험했다.

데이터는 처음에 \(d\)개 선택하고 이 중 \(d\)보다 적은 수의 \(N\)개 source만을 선택한다. 그 다음 augmentation을 통해 \(d-N\)개의 이미지를 생성하면 결국 총 \(d\)개의 이미지를 학습하게 된다.

여러가지 augmentation 을 사용한다.

이미지 a는 사진이고 b는 손으로 그린 그림이다. c는 crowdedness를 비교하기 위한 케이스이다.



Self-supervised pretext task로는 위의 세 가지를 주로 이용한다.

각 층에서의 성능을 비교하기 위해 각 층마다 linear probes를 달아준다. linear probes는 하나의 linear classifier를 더 달아주는 것을 의미한다.
ImageNet과 CIFAR-10/100에 대해서 학습을 시키고 linear classifier의 정확도를 측정하기 위해서는 ImageNet validation set을 이용한다.

3가지 Augmentation(scale, rotation, jitter)을 비교했을 때 하나만 사용했을 때는 scale이 제일 좋았고 결론적으로 모두 활용했을 때 가장 효과가 좋았다.

Single source image를 사용했을 때 (\(N=1\)) 성능은 random initialization보다 훨씬 좋았다. 또한 scattering network 보다도 처음 1,2 층에서 성능이 더 좋았다.

BiGAN을 보면 1~3층에서는 단 한 장의 이미지를 사용한 경우가 모든 이미지를 다 사용한 경우보다 성능이 좋았다.
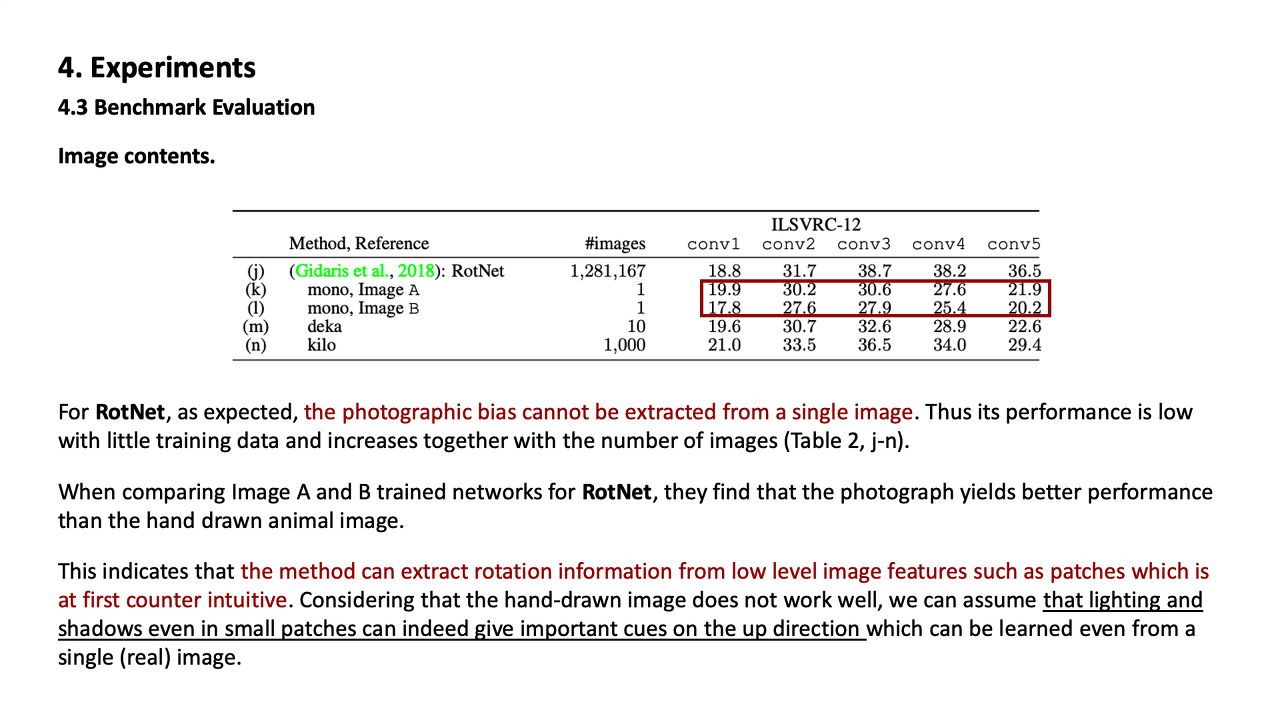
RotNet의 경우는 단 하나의 이미지에서 photographic bias를 추출할 수 없었고 그 때문에 성능이 낮게 나왔다.
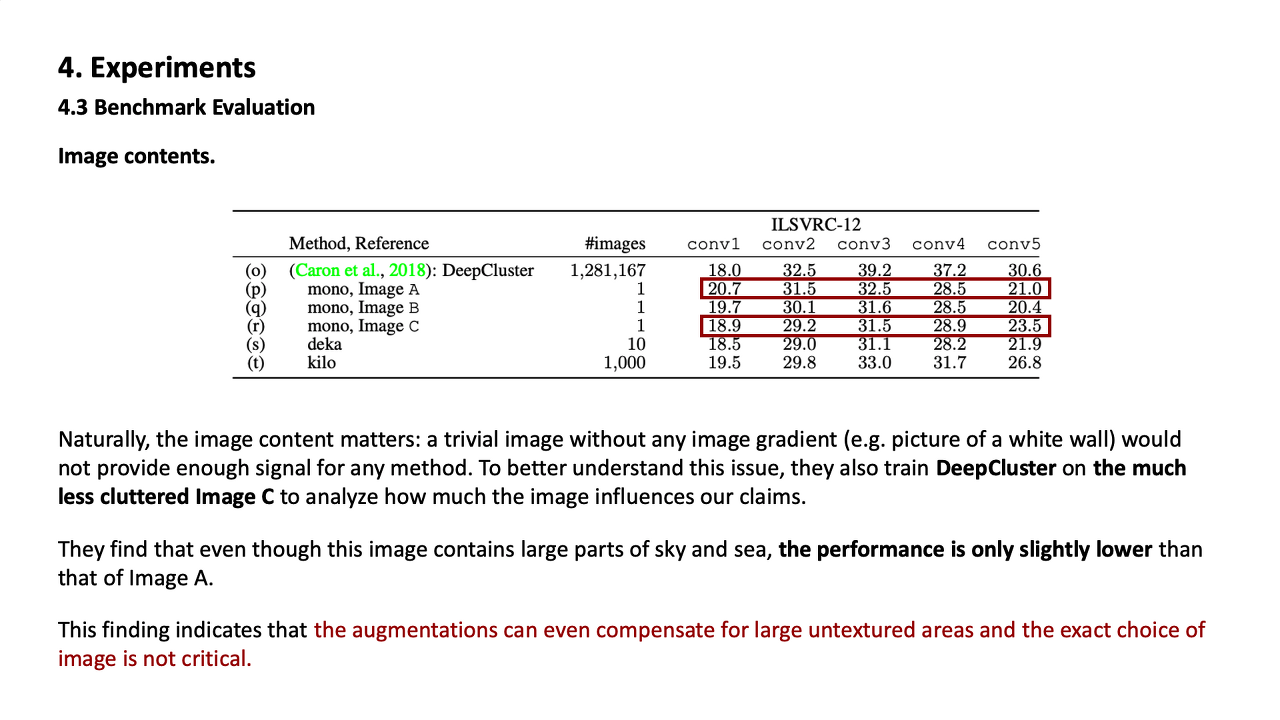
Crowdedness를 비교하기위해 DeepCluster를 사용했는데 이 때 바다와 하늘로만 구성된 사진인 image C와 사람이 가득했던 image A와의 성능이 그렇게 차이가 나지 않았다. 이는 augmentation이 large untextured areas를 보상할 수 있고 이미지의 선택이 그렇게 중요하지 않다는 것을 의미한다.

사진을 한장만 이용하는 MonoGAN의 경우 conv1, 2에서 성능이 좋았다. 그러나 층이 deep해질수록 성능차이는 커졌고 이는 단 한 장의 사진으로는 네트워크가 high level concepts를 배우지 못함을 뜻한다고 주장했다.

Conv1 을 시각화했을 때 다음과 같다. 그러나 시각화된 모습이 성능을 예측하는데 도움이 되지는 못한다. 예를 들어, BiGAn의 경우 많은 edge detector를 보여주는데 deepcluster는 반복되는 point feature를 많이 보여준다.
하지만 그들의 성능은 비슷하다.

만일 freeze 시키지 않고 전체 네트워크를 finetune했을 때 그 성능은 fully-supervised 네트워크의 성능으로 회복이 가능했다.

한 장의 이미지로 학습시킨 MonoBiGAN을 통해 얻은 feature들을 style transfer에 사용하면 supervised의 것과 그렇게 크게 차이가 나지 않는 것을 볼 수 있다.

다 읽고..
결론은 한 장의 이미지를 augmentation하여 사용하면 어느 정도 괜찮은 feature들을 뽑아낼 수 있다는 것이다. 아, 그리고 물론 conv1, conv2 쯤에 한정적으로 말이다. 학습할 이미지의 수가 굉장히 적은 편이라면 어느 정도 괜찮은 방법이 되겠지만 굳이 이미지가 많이 준비되어 있는 환경에서는 적당한 augmentation만 하면 될 것 같다.
Comments